Redis란 무엇일까
Redis란 무엇일까

Redis는 key-value 구조의 데이터를 저장하기 위한 NoSQL DBMS이다. 데이터를 메모리에 저장하여 데이터 접근 속도가 빠르다는 장점이 있다. 보통 캐시나 메시지 브로커로 활용한다.
인 메모리 데이터베이스이나, 데이터를 디스크에 저장하거나 스냅샷을 남기는 등으로 영속성을 유지할 수 있다. 또한 싱글 쓰레드로 동작하기 때문에 멀티 쓰레드 환경에서 발생할 수 있는 동시성 문제, 데드락 등을 방지할 수 있다. 다만 트래픽이 폭증하면 싱글 쓰레드 환경에서 처리량 한계에 도달하기 쉬운데, 레플리케이션을 통해 읽기 요청을 슬레이브에 분산시키는 방식으로 안정성을 챙길 수 있다.
Redis의 특징
동작
Redis의 모든 데이터는 디스크가 아니라 메모리에 존재한다. 디스크에서 데이터를 찾는 것보다 메모리에서 데이터를 찾는 것이 월등히 빠르다.
또한 Redis는 메모리 관리에 최적화된 C언어 기반의 자료 구조를 사용한다. 일반적인 C언어 문자열은 끝에 널 문자(\0)로 끝을 표기한다. 따라서 문자열의 전체 길이를 알기 위해서는 처음부터 끝까지 세어야 한다. 그러나 Redis는 SDS(Simple Dynamic String)이라는 독자적인 문자열 구조체를 사용한다. SDS는 문자열 데이터와 현재 길이, 남은 공간 정보를 같이 저장한다. 따라서 문자열 길이를 $O(1)$에 구할 수 있다. 또한 데이터가 수정될 때마다 메모리를 새로 할당하는 비용을 구하기 위해 미리 여유 공간을 할당하는 전략을 사용한다.
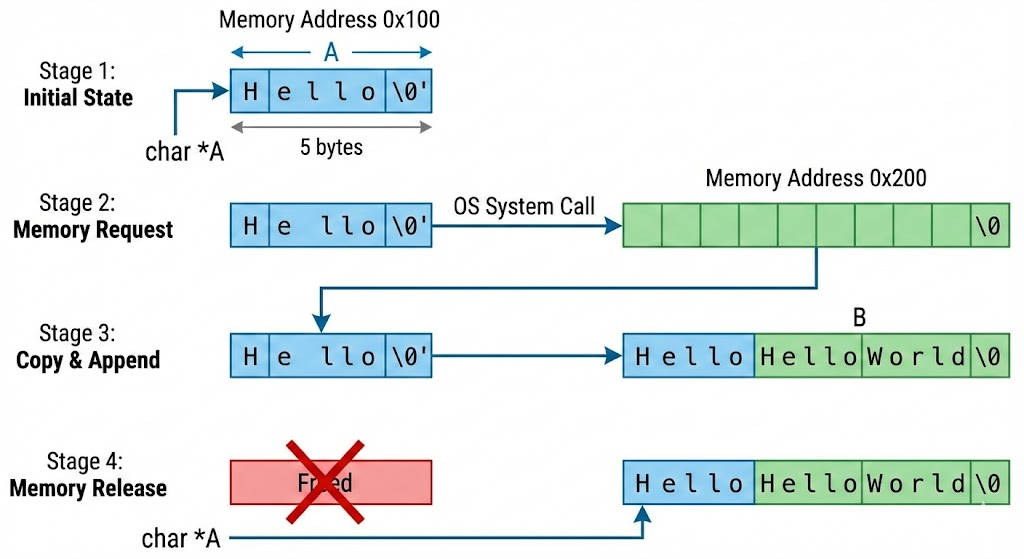
일반적인 C언어 환경에서 문자열 뒤에 새로운 문자열을 붙이는 작업을 생각해보자. 문자열 A의 크기는 5바이트이고, 여기에 5바이트의 문자열 B를 붙이려고 한다. 먼저 OS는 시스템 콜을 통해 10바이트의 메모리를 요청한다. 이후 A를 해당 메모리에 복사하고, B를 뒤에 붙인다. 마지막으로 이전에 문자열 A가 위치한 메모리를 삭제한다.
만약 위 작업을 자주 수행한다고 가정하자. 데이터를 복사하고 메모리를 할당하는 작업은 무거운 연산이다. 이는 성능 저하로 이어진다.
Redis는 문자열을 수정할 때 필요한 크기보다 더 여유 있게 메모리를 할당한다. 변경 후 문자열의 크기에 따라 다른 규칙을 적용한다.
- 만약 1MB보다 작다면 필요한 만큼의 공간을 추가로 할당한다. 예를 들어 수정 후 크기가 100바이트라면, 실제로는 200바이트를 할당하는 것이다.
- 만약 1MB 이상이라면 1MB의 추가 공간을 할당한다. 예를 들어 수정 후 크기가 50MB라면, 더블링을 하는 경우 100MB로 자칫 메모리 낭비가 발생할 수 있다. 따라서 1MB만 할당하는 것이고, 결과적으로 51MB를 할당한다.
Redis의 이러한 전략의 핵심은 시스템 콜 횟수의 감소이다. 이를 통해 CPU의 부하를 줄이고 데이터 쓰기 속도를 효과적으로 높일 수 있다.
Redis는 싱글 쓰레드로 명령을 처리한다.
멀티 쓰레드는 CPU가 쓰레드 간 문맥 교환하는 과정에서 비용이 발생하는데, 싱글 쓰레드는 그렇지 않다.
또한 멀티 쓰레드는 여러 쓰레드가 같은 메모리 자원에 접근하는 것을 방지하기 위해 락을 거는데, 싱글 쓰레드는 그럴 필요가 없다.
또한 싱글 쓰레드는 하나의 CPU 코어만 사용하므로 캐시 히트율이 높아진다.
멀티 쓰레드 환경에서 두 쓰레드 A, B가 있다고 하자. 쓰레드 A가 작업하면서 L1, L2 캐시에 자신의 데이터를 채울 것이다. 이후 문맥 전환이 발생하여 쓰레드 B가 작업하면, 캐시에 A의 데이터를 밀어내고 자신의 데이터를 채울 것이다. 따라서 멀티 쓰레드 환경에서는 캐시 미스가 싱글 쓰레드 환경에 비해 자주 발생하게 되는 것이다.
의존성이 적다
Redis는 특정 OS, 프로그래밍 언어 등에 종속되지 않고 유연하게 동작한다.
Redis는 설치 및 실행을 위해 복잡한 설정이나 라이브러리를 설치할 필요가 없다. 예를 들어 자바는 JDK나 JVM이 필요하고, 파이썬은 인터프리터가 필요한데 Redis는 컴파일된 바이너리 파일만 있으면 동작한다. Redis는 C언어로 작성되었기에, 컴파일 과정만 거치면 CPU가 바로 이해할 수 있는 기계어로 변환되기 때문이다.
Redis가 외부 라이브러리에 의존하지 않는 비결은 정적 링킹이다. 보통의 프로그램은 실행될 때 OS에 존재하는 라이브러리 파일을 찾아 사용한다(== 동적 링킹). 그러나 Redis는 컴파일할 때 필요한 라이브러리들을 실행 파일(redis-server) 안에 포함시킨다.
이러한 특징 때문에 컴파일한 redis-server 파일을 다른 서버로 옮겨 바로 실행할 수 있으며, 의존성이 맞지 않아 실행되지 않는 문제가 발생하지 않는다. 또한 이는 Redis 도커 이미지가 가벼운 이유이다. 최소한의 OS 커널 위에 Redis 바이너리 파일만 추가하면 되기 때문이다.
초기 구동 시 점유하는 메모리가 매우 적고, 실행 오버헤드가 거의 없다. 따라서 컨테이너 환경에서 가볍게 배포할 수 있다.
Tomcat이나 Kafka와 같은 JVM 기반 애플리케이션은 JVM이라는 가상 머신이 먼저 띄워져야 하기 때문에, JIT 컴파일러, GC 쓰레드 등이 로딩되고, 아무런 데이터가 없어도 이미 많은 메모리를 미리 확보하게 된다. 그러나 Redis는 구동하기 위한 최소한의 자료구조만 생성하기 때문에 초기에 아주 적은 메모리만 점유한다.
또한 명령을 수행하기 위해 복잡한 파싱 과정을 거치지 않는다. 일반적인 RDB는 쿼리를 수행하기 전, SQL 문법을 검사하고, 테이블이 존재하는지 확인하며, 실행 계획을 세우고, 데이터를 조회한다. 그러나 Redis는 문법 검사나 실행 계획 없이 바로 메모리 주소로 가서 데이터에 접근한다.
메모리를 효율적으로 사용하기 위해 malloc 대신 페이스북의 jemalloc을 사용한다. jemalloc은 메모리 파편화를 최소화하며 메모리를 점유한다.
그리고 싱글 쓰레드이기 때문에 문맥 전환 비용이 발생하지 않는다.
Redis는 애플리케이션 코드 내부에서 동작하는 것이 아니라 외부에서 별도로 동작한다. 만약 Spring이나 Node.js와 같은 애플리케이션의 내부 변수에 캐시 데이터를 저장했다면, 서버를 재시작하거나 다운될 때 캐시 데이터 또한 삭제될 것이다. 그러나 Redis는 별도의 프로세스에서 실행되므로, 애플리케이션 서버의 상태와 무관하게 Redis의 세션과 데이터는 그대로 유지된다.
각 서버가 상태를 가지지 않는 대신, Redis에 저장함으로써 상태가 공유되는 것처럼 동작하게 할 수 있다. 현대의 WAS는 스케일 아웃을 통해 여러 서버에서 동작한다. Redis를 사용하면 여러 서버가 공통된 캐시 데이터에 접근할 수 있게 된다.
WAS A에서 로그인을 한 후, 다음 요청이 로드 밸런서에 의해 WAS B로 전달되었다고 하자. Redis가 없다면 세션 불일치로 인해 재로그인을 요구할 것이다. 그러나 Redis를 사용하면 WAS B가 Redis를 보고 로그인한 사용자임을 인식할 수 있다. 이를 세션 클러스터링이라고 한다.
DB 캐싱 또한 가능하다. WAS A가 DB에서 데이터를 읽은 후 Redis에 넣으면, 다른 WAS는 DB를 거치지 않고 Redis에서 데이터에 접근할 수 있게 된다.
Redis는 TCP 기반 프로토콜인 RESP(Redis Serialization Protocol)를 사용한다.
RESP는 데이터의 맨 앞에 붙는 접두사를 보고 데이터가 어떤 형태인지 판단한다. 예를 들어 +라면 짧은 상태 메시지임을 의미한다. 긴 문자열의 경우 데이터 앞에 길이 정보를 먼저 보낸다.
또한 클라이언트는 명령어를 배열(*)로 묶어서 보낸다. 예를 들어 SET hello world는 다음과 같이 변환되어 전송된다.
1
2
3
4
5
6
7
*3\r\n // 배열 크기는 3
$3\r\n // 첫 번째 데이터는 3글자
SET\r\n // 내용은 SET
$5\r\n
hello\r\n
$5\r\n
world\r\n
일반적인 HTTP 요청은 JSON 형태로, 이를 파싱하는 과정은 복잡하다. 그러나 RESP는 복잡하게 문자열을 탐색하지 않고 단순히 포인터를 이동하고 숫자를 읽음으로써 CPU 사이클을 아낄 수 있다.
또한 거의 모든 프로그래밍 언어는 Redis 클라이언트 라이브러리가 존재한다. DB 연결을 설정할 필요 없이 코드로 Redis를 연결하여 사용할 수 있다.
기존 시스템에 Redis를 추가하기 좋다. MySQL을 사용하는 시스템이 느려진 경우, Redis를 앞단에 붙이면 성능을 개선할 수 있다. 이를 Look-aside 또는 Lazy Loading 패턴이라고 한다.
클라이언트가 데이터를 요청하면 WAS는 Redis에 데이터가 있는지 확인한다. 만약 있다면 DB를 거지치 않고 Redis의 데이터에 접근한다.
Redis에 원하는 데이터가 없다면 DB에 접근하여 데이터를 가져온 후, Redis에 저장하고 클라이언트에게 전달한다. 이후 같은 요청이 오면 Redis에서 데이터를 가져오면 된다. 데이터가 실제로 필요할 때 Redis에 적재하기 때문에 Lazy Loading 패턴이라고 불리는 것이다.
그러나 DB의 데이터는 변경되었으나 Redis 데이터는 그렇지 않다면 데이터 불일치가 발생하게 된다. 이를 해결하는 가장 일반적인 방법은 데이터를 삭제하는 것이다.
DB의 데이터를 변경한 후, Redis에 저장된 기존 데이터를 찾아 삭제한다. 이후 해당 데이터에 대한 요청이 들어오면, Redis에 데이터가 없으므로 DB에서 데이터를 가져온 후, Redis에 넣는다.
활용 분야
Redis는 DB의 부하를 줄이기 위해 global cache로 사용된다. DB에서 자주 조회되는 데이터를 Redis에 저장함으로써 디스크 I/O를 줄여 응답 속도를 줄일 수 있으며, 트래픽 폭주 시 DB가 다운되는 것을 막는다.
또한 여러 서버의 공용 세션 저장소로 사용될 수 있다. 사용자의 세션 정보를 Redis에 저장하면 각 서버는 Redis에서 로그인 정보를 확인하면 되므로 서버 간 상태 공유가 가능해진다. 또한 TTL을 설정하여 자동 로그아웃 기능을 쉽게 구현할 수 있다.
로그인 시 발급한 Refresh Token을 저장하거나 로그아웃된 토큰을 블랙리스트로 관리할 때 Redis를 사용하기도 한다. 역시 TTL을 설정하여 자동 삭제되도록 구현할 수 있으므로 편리하다.
Redis를 메시지 큐로 활용하여 비동기 처리 및 통신을 할 수 있다. 다량의 간단한 작업들을 Redis에 넣고, Redis는 이를 하나씩 꺼내 수행하도록 하면 사용자는 기다릴 필요가 없다.
또한 Pub/Sub 모델을 지원하기 때문에 실시간 채팅 및 알림 기능에 사용될 수 있다.
속도
Redis는 데이터를 디스크가 아니라 메모리에 저장한다. 일반적인 DB는 데이터를 찾기 위해 디스크를 탐색하는데, 이 과정에서 발생하는 디스크 I/O는 메모리 접근 시간에 비해 매우 긴 시간이다. 메모리에 접근하는 속도가 디스크보다 수백 배에서 수천 배 빠르다.
Redis는 오직 데이터 접근에 초점을 맞춘다. DB는 데이터를 찾을 때 SQL을 파싱하고, 계획을 세우고 접근하지만 Redis는 key를 기반으로 해시 테이블을 통해 한 번의 연산으로 데이터가 있는 메모리 주소를 찾아 접근한다.
또한 기본적으로 트랜잭션의 격리 수준이나 쿼리 옵티마이저같은 기능이 빠져 있어 엔진이 가볍다. 그리고 RESP 프로토콜을 통해 통신 비용조차 최적화했다.
마지막으로 싱글 쓰레드이기 때문에 락과 같은 기능이 없고, 문맥 전환에서 발생하는 오버헤드가 발생하지 않는다.
기능
일반적인 key-value 저장소를 value를 단순히 문자열로 저장하지만 Redis는 일반적인 프로그래밍 언어에서 사용하는 자료구조를 데이터 타입으로 지원한다. 정렬, 중복 제거와 같은 개발자가 애플리케이션 코드에서 처리해야 할 로직을 Redis에게 맡길 수 있다.
지원하는 데이터 타입은 다음과 같다.
String: 텍스트, 숫자, 바이너리 파일 등을 저장할 수 있다. 최대 512MBList: 순서가 있는 문자열 리스트, 메시지 큐를 구현하는 데 사용Set: 순서가 없고 중복을 허용하지 않는 리스트Sorted Set:Set에 score가 추가된 형태, 자동 정렬됨Hash: field-value 쌍으로 이루어진 구조로 객체 데이터를 저장하기 적합하다.- 이외에도 위치 기반 데이터를 다루는
Geospatial, 대용량 데이터 개수를 추정하는HyperLogLog, 비트 단위 연산인Bitmap, 로그 처리를 위한Stream등이 있다.
Redis는 데이터를 메모리에 저장하기 때문에 Redis가 종료되면 데이터가 사라진다. 이를 방지하기 위해 데이터를 디스크에 저장한다. 크게 두 가지 기능이 존재한다.
RDB(Redis Database): 특정 간격마다 현재 메모리 상태를 스냅샷(.rdb)으로 저장하는 방법이다. 백업 파일의 크기가 작고 로딩 속도가 빨라 복구 시 유리하지만, 스냅샷 사이에 서버가 다운되면 그 사이 데이터는 유실될 수 있다.AOF(Append Only File): 모든 쓰기 명령을 로그 파일에 기록하는 방법이다. 데이터 유실을 최소화할 수 있으나 로그 파일의 크기가 계속 커지며, 복구 시 처음부터 명령어를 실행해야 하기 때문에 복구 속도가 느리다.
일반적으로 두 방법을 혼용하여 사용한다.
서비스가 커지면 Redis 서버 하나로는 부족할 수 있다. 이를 위해 레플리케이션, 자동 복구, 분산 저장 기능 등을 제공한다.
Replication
레플리케이션을 구성하면 Redis 서버들은 마스터와 슬레이브라는 상하 관계를 가진다.
마스터는 원본 데이터를 관리하며, 모든 데이터의 쓰기, 수정, 삭제 요청을 수행할 수 있는 권한을 가지고 있다. 하나의 마스터는 여러 개의 슬레이브를 가질 수 있다.
슬레이브는 주기적으로 마스터의 데이터를 복사하여 유지한다. 기본적으로 읽기 전용이며, 데이터를 직접 수정할 수 없다.
대부분의 웹 서비스는 쓰기 요청보다 읽기 요청의 비율이 월등히 높다. 따라서 쓰기 요청은 마스터 하나가 전담하고, 읽기 요청은 여러 대의 슬레이브가 나누어 처리하는 방식으로 부하를 분산한다. 트래픽이 폭주해도 슬레이브만 scale out하면 읽기 성능을 무한히 확장할 수 있다.
또한 슬레이브는 마스터에 장애가 발생했을 때를 대비한 일종의 보험이다. 슬레이브는 마스터와 똑같은 데이터를 가지고 대기하고 있다. 만약 마스터가 다운되면 슬레이브 중 하나가 즉시 사용되어 데이터를 제공할 수 있다.
예를 들어 Redis 데이터를 디스크에 저장하는 작업은 CPU를 많이 사용하는데, 사용 중인 마스터에서 이 작업을 수행한다면 일시적으로 멈춤이 발생할 수 있다. 따라서 백업 작업은 여유로운 슬레이브에서 수행하여 마스터의 성능 저하를 방지할 수 있다.
Redis의 레플리케이션은 비동기 방식으로 동작한다. 마스터에 슬레이브가 처음 연결되면, 마스터는 현재 메모리 상태를 스냅샷으로 찍어 슬레이브에게 전달한다. 슬레이브는 이를 받아 자신의 메모리에 로드한다.
초기화 과정이 끝나면 마스터는 이후 받는 모든 쓰기 명령을 슬레이브에게 실시간 스트림으로 전송한다. 슬레이브는 마스터의 명령을 따라하며 데이터 싱크를 맞춘다.
만약 네트워크 문제로 슬레이브가 명령을 받지 못하면 싱크가 맞지 않는 문제가 발생할 수 있다. 이를 방지하기 위해 Replication Backlog 라는 버퍼가 존재한다.
마스터는 슬레이브에게 보낼 명령어들을 큐 형태의 메모리 공간에 잠시 저장한다. 그리고 슬레이브는 자신이 어디까지 명령을 따라했는지 위치(offset)를 기억한다. 이를 통해 싱크가 맞지 않을 때 놓친 부분만 이어서 받아 싱크를 맞출 수 있다.
다만 비동기적이기 때문에 마스터에 데이터가 들어간 직후 아주 짧은 순간 슬레이브에는 데이터가 아직 없을 수 있다. 이를 Replication Lag(복제 지연)이라고 한다. 실시간성이 매우 중요한 서비스는 이를 고려해야 한다.
Sentinel
Sentinel은 레디스의 고가용성을 확보하기 위한 방법이다.
센티널은 Redis 서버들을 감시하는 관리자 시스템이라고 할 수 있다. 센티널이 수행하는 동작은 다음과 같다.
- 마스터와 슬레이브가 제대로 응답하는지 일정 주기마다 핑을 날려 확인한다.
- 마스터가 다운되었다고 판단되면 슬레이브 중 하나를 골려 마스터로 승격시킨다. 그리고 나머지 슬레이브는 새로운 마스터를 따르도록 설정을 변경한다.
- 클라이언트에게 마스터 IP와 같은 설정 정보를 전달한다.
센티널 하나가 단독으로 결정을 내리지 않는다. 잘못된 결정을 막기 위해 여러 개의 센티널이 함께 사용된다(최소 3개 권장).
예를 들어 센티널 A가 마스터에게 핑을 보냈으나 응답이 없다고 하자. A는 ‘주관적’으로 마스터가 다운되었다고 판단한다. 이를 SDOWN, Subjective Down(주관적 다운) 이라고 한다.
이후 A는 다른 센티널 B, C에게 마스터가 다운된 것으로 판단하는지를 물어본다. 일정 quorum 이상의 센티널이 동의하면, 공식적으로 마스터가 다운되었다고 확정한다. 이를 ODOWN, Objective Down(객관적 다운) 이라고 한다.
ODOWN이 선언되면 투표를 통해 장애 복구를 이끌 ‘리더 센티널’을 뽑는다. 리더 센티널은 마스터와 연결이 끊긴 지 오래되지 않았고(== 데이터가 최신화되어 있음) 우선순위가 높은 슬레이브를 고른 후, 마스터로 승격시킨다. 그리고 나머지 슬레이브들에게 새로운 마스터를 따르도록 명령한다. 이후 다운된 마스터가 복구되면 해당 마스터를 새로운 마스터의 슬레이브로 강등시킨다.
Cluster
Redis의 Cluster를 통해 하나의 서버 메모리 한계를 넘어 데이터를 저장할 수 있고, 쓰기 성능을 높일 수 있다.
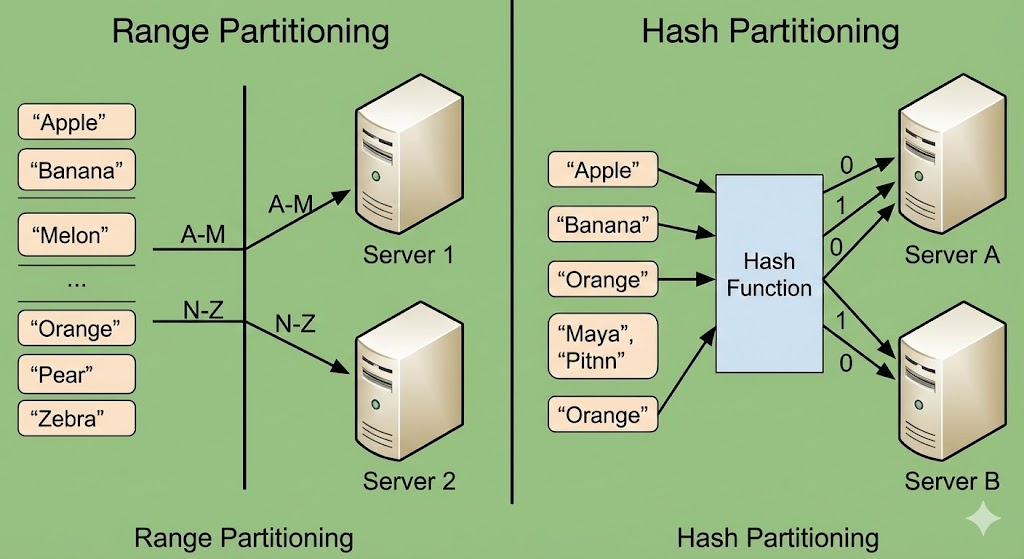
일반적인 분산 시스템은 데이터를 나눌 때 데이터를 구간으로 나누어 서버에 분산시킨다. 그러나 Redis Cluster는 해시 슬롯을 통해 데이터를 쪼갠다.
Redis Cluster는 전체 데이터를 16,384개의 슬롯으로 쪼갠 후, 노드들에게 분배한다. 이후 데이터가 들어오면 공식(CRC16(key) % 16384)을 통해 몇 번 슬롯에 들어갈지를 결정한다. 나중에 새로운 노드가 추가되면 일일히 계산할 필요 없이 슬롯만 떼어 주면 되기에 확장에 유연하다. 공식을 보면 노드 개수는 공식에 종속적이지 않기 때문이다.
CRC16은 Cyclic Redundancy Check의 약자로, 네트워크 통신에서 에러가 발생했는지를 확인하기 위한 알고리즘이다. 다만 여기서는 단순히 문자열의key를 0부터 65,535 사이의 정수로 바꿔주는 컨버터라고 생각하면 된다.
센티널 구조와 비교했을 때 가장 큰 차이점은 쓰기를 담당하는 마스터가 여러 개라는 점이다. 센티널 구조는 마스터가 오직 한 개이기 때문에 쓰기 요청이 폭주하면 마스터가 버티질 못하지만, 클러스터 구조는 마스터가 여러 개라면 쓰기 요청 또한 분산된다. 이론적으로 노드를 늘리는 만큼 쓰기 성 또한 선형적으로 증가한다. 예를 들어 마스터의 가용 용량이 5GB일 때, 마스터가 5개 존재하면 총 25GB의 데이터를 메모리에 올릴 수 있는 것이다.
클러스터는 중앙 관리자가 없는데, 만약 클라이언트가 아무 노드에게 접근하여 데이터를 요청하면 어떻게 반응할까?
클라이언트가 노드 A에 접근하여 데이터를 요구한다. A가 판단했을 때 해당 데이터는 노드 C가 담당하고 있다고 할 때, A는 클라이언트에게 데이터를 주지 않고 에러를 반환한다. 에러에는 노드 C에서 다시 요청하라는 메시지가 담겨 있다. 이후 클라이언트는 노드 C에서 다시 요청하여 데이터를 받는다.
다만 매번 이렇게 동작하면 재시도로 인해 결과적으로 느리게 동작할 것이다. 대부분의 Redis 라이브러리는 슬롯 위치를 캐싱하고 있어서 처음부터 알아서 맞는 노드로 찾아간다.
마지막으로 Redis Cluster는 센티널 없이도 스스로 장애를 복구한다. 각각의 마스터 노드는 자신의 데이터를 복제하는 슬레이브를 가진다. 모든 노드는 서로 Gossip Protocol을 통해 살아있는지 확인한다. 만약 특정 마스터가 죽으면 다른 마스터들이 투표하여 적합한 슬레이브를 새로운 마스터로 승격시킨다. 즉, Cluster 기능 안에 Sentinel의 역할이 포함되어 있다.
vs. RDB
가장 큰 차이점은 Redis는 데이터를 메모리에, RDB는 디스크에 저장한다는 것이다.
또한 Redis는 NoSQL DB이므로 스키마가 없으며, 데이터 간 관계가 없다. 조인 연산이 불가능하다.
Redis는 안정성보다 성능에 초점을 맞춘다. 기본적으로 비동기적 레플리케이션 및 백업을 사용하긴 하나, 서버가 갑자기 다운된다면 마지막 순간의 데이터는 유실될 수 있다. 또한 트랜잭션 기능이 있으나 RDB만큼 강력하지는 않다.
반면 RDB는 데이터 무결성에 초점을 맞춘다. ACID 속성을 철저히 보장하며, 트랜잭션 도중 장애가 발생하면 롤백을 통해 무결성을 지킨다.
Redis는 key-value 저장소이기 때문에 key 기반 조회 속도가 매우 빠르다. 다만 복잡한 검색은 비효율적이다. RDB는 SQL을 통해 복잡한 조건 또한 검색 및 집계할 수 있다.
Redis는 scale out이 비교적 쉽다. Redis Cluster를 통해 데이터를 샤딩하는 것이 편리하다. RDB에서 샤딩을 하려면 로직이 매우 복잡해지거나 관리가 까다로워진다.
만약 User 테이블은 서버 A에, Order 테이블은 서버 B에 있다고 가정하자. 그렇다면 아래 쿼리는 실행할 수 없다.
1
2
SELECT * FROM User u
JOIN Order o ON u.id = o.user_id;
위 문제를 해결하기 위해 애플리케이션 레벨에서 데이터를 조립해야 하는데, 결국 DB에 해야 할 일을 애플리케이션이 수행해야 하므로 코드가 난잡해지고 성능이 느려질 수 있다.
이외에도 트랜잭션, resharding 등과 같은 복잡한 문제들이 있기에, RDB에서 scale out을 적용하기에는 어렵다.
보통 둘 중 하나만 사용하지 않고 함께 사용한다. RDB에 데이터를 저장하고 Redis에서 자주 사용되는 데이터를 캐싱하거나 빠른 처리가 필요한 임시 테이터를 처리한다.
vs. Memcached
Redis와 Memcached는 모두 인 메모리 key-value 저장소라는 공통점이 있다. 과거에는 Memcached가 캐시 표준이었으나 현재는 더 기능이 풍부한 Redis가 de facto standard이다.
Memcached는 String 타입만 지원하지만, Redis는 String, Sorted Set 등 다양한 자료구조를 지원한다.
Memcached는 멀티 쓰레드를 지원한다. CPU 코어가 많은 서버에서 하나의 인스턴스를 띄워도 모든 코어를 활용하여 성능을 극대화할 수 있으나 내부적으로 락 관리를 해야 한다. Redis는 기본적으로 싱글 쓰레드이다.
Memcached는 서버끼리 서로 통신하지 않아, 클라이언트가 데이터를 어느 서버에 넣을지 직접 계산하여 찾아간다. 반면 Redis는 Gossip Protocol로 서로 통신하여 클러스터를 형성하고, 때문에 클라이언트가 아무 노드에 접근해도 찾고자 하는 데이터는 다른 서버에 있다고 안내받을 수 있다.
Memcached는 프로세스가 다운되면 데이터는 사라진다. 복구 기능이 없다. 반면 Redis는 RDB와 AOF를 통해 디스크에 데이터를 저장하기 때문에 재부팅되어도 데이터를 복구할 수 있다.
현대적인 아키텍처에서 Redis가 Memcached의 기능을 완전히 포함하기 때문에 Redis를 더 많이 선택하는 편이다.