Redis의 자료형과 명령어 - String
Redis의 자료형과 명령어 - String
정렬과 큐와 같이 개발자가 코드에서 직접 구현해야 했던 복잡한 자료구조 로직을 레디스가 대신 수행해준다.
redisObject
레디스는 저장되는 데이터의 형태와 크기에 따라 내부적으로 저장 방식을 최적화한다.
레디스의 모든 value는 redisObject 라는 구조체로 감싸져 있다. 일종의 메타데이터라고 보면 된다.
1
2
3
4
5
6
7
struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:24;
int refcount;
void *ptr;
};
type 은 데이터 타입을 나타낸다. 4비트 크기를 가지며, REDIS_STRING (문자열, 0), REDIS_LIST (리스트, 1), REDIS_SET (집합, 2), REDIS_ZSET (정렬된 집합, 3), REDIS_HASH (해시, 4) 등과 같은 값을 가질 수 있다.
encoding 은 데이터가 실제로 메모리에 어떻게 저장되어 있는지를 나타낸다. 4비트 크기를 가지며, type 이 같아도 encoding 은 달라질 수 있다.
lru 는 객체가 마지막으로 접근된 시간을 기록하는 필드이다. 24비트 크기를 가지며, 메모리가 꽉 찼을 때 어떤 데이터를 삭제할지 결정하기 위해 사용된다.
refcount 는 해당 객체가 몇 군데에서 참조하고 있는지를 담는 필드이다. 이 값이 0이라면 아무도 안 쓰는 객체이므로 메모리에서 해제한다.
ptr 은 진짜 데이터가 저장된 위치를 가리키는 포인터이다. 64비트 운영체제라면 ptr의 크기는 64비트(8byte)이다.
String
String 자료형은 단순히 텍스트만 저장하는 것이 아니라 정수, 실수, 바이너리 데이터까지 저장할 수 있다.
String은 C언어의 문자열과 달리 중간에 널 문자(\0)가 포함되어도 문자열의 끝으로 인식하지 않는다. 별도로 기록한 길이 정보를 통해 데이터를 인식한다. 따라서 어떤 형태의 바이너리 데이터라도 안전하게 저장할 수 있다.
레디스는 SDS(Simple Dynamic String) 이라는 구조체로 문자열을 표현한다. SDS는 길이 정보를 가지고 있기 때문에 $O(1)$에 길이를 구할 수 있으며, 여유 공간을 미리 확보하여 데이터 수정 시 발생하는 오버헤드를 줄인다.
하나의 key에 저장할 수 있는 value의 최대 크기는 512MB이다. 다만 레디스는 싱글 쓰레드로 동작하기 때문에 하나의 key에 너무 큰 데이터를 넣고 빼는 것은 시스템에 영향을 줄 수 있다.
예를 들어 500MB 데이터를 GET 명령으로 읽는다고 가정하자. 데이터가 크므로 이를 네트워크로 전송하는 데에는 비교적 오랜 시간이 걸릴 것이다. 그리고 전송 시간 동안 다른 요청은 처리하지 못하게 된다.
레디스 서버의 네트워크 대역폭이 1Gbps(== 초당 약 125MB 전송)이라고 가정하자. 만약 512MB 데이터를 조회하게 되면, 약 4초 동안 네트워크 대역폭을 혼자 채우게 되며, 다른 서비스들이 통신할 수 없게 된다.
따라서 보통 데이터를 잘게 쪼개서 저장하거나, S3같은 저장소에 저장한 후 링크만 레디스에 캐싱하는 것이 일반적이다.
INCR, DECR 와 같은 연산은 원자성을 보장한다. 즉, 여러 클라이언트가 동시에 명령을 수행해도 동시성 문제 없이 정확하게 수행된다. 이는 레디스가 싱글 쓰레드로 동작하는 것에 기인한다.
또한 메모리 값을 읽고, 증가/감소시키고 다시 저장하는 과정을 단 하나의 동작으로 처리하기 때문이다.
일반적인 RDB나 멀티 쓰레드 환경이라면 락을 통해 동시성 문제를 해결해야 할 것이다. 레디스의 싱글 쓰레드 구조가 하나의 거대한 락 역할을 한다고 볼 수도 있겠다.
인코딩 방식
redisObject 의 String 타입에서 가능한 encoding 방식은 아래와 같다.
int
int 는 값이 정수이고 64비트 범위 내일 때 사용하는 인코딩 방식이다. 이 경우 별도의 문자열 할당 없이 ptr에 숫자 그 자체를 저장한다. 즉, 별도의 SDS를 생성하지 않는다. 이는 메모리를 가장 적게 사용하는 방법이다. 메모리 할당 횟수를 줄이고 CPU가 메모리를 두 번 참조하는 비용이 사라지는 것이다.
또한 레디스는 0부터 9999까지의 숫자는 서버가 시작될 때 미리 만들어 놓는다. 예를 들어 SET key 100 명령을 입력하면, 새로운 redisObject 를 만드는 것이 아니라 이미 만들어져 있는 100번 객체를 재사용한다.
embstr
embstr 는 크기가 44바이트 이하인 작은 문자열일 때 사용하는 방식이다. 단 한 번의 메모리 요청(malloc) 으로 redisObject 구조체와 실제 데이터(sdshdr)를 연속된 공간에 넣는다.
그렇다면 왜 하필 44바이트일까? 레디스가 사용하는 jemalloc의 할당 단위와 CPU 캐시 라인 크기 때문이다.
보통 CPU는 메모리를 읽을 때 캐시 라인 단위(64바이트)로 가져오길 원한다. 따라서 레디스는 embstr 객체 하나의 크기를 정확히 64바이트로 맞추기 위해 노력한다.
먼저 redisObejct 의 크기는 총 16바이트이다. 그리고 sdshdr8의 헤더의 크기는 3바이트이며, 널 문자를 위한 공간 1바이트를 제외하면, 64바이트 블록 하나에 넣을 수 있는 순수한 데이터의 최대 크기가 44바이트이다.
이러한 방식이 캐시 효율을 높이는 방법이다. 레디스가 키의 값을 읽으려고 하는 상황을 생각해보자. CPU는 일단 redisObject 를 읽어야 type이 뭔지 알 수 있다. 따라서 redisObject 를 가져오면서 주변 64바이트 메모리까지 캐시에 가져온다. encoding 방식이 embstr 이라면 redisObject 뒤에 sdshdr 이 존재할 것이므로, 주변 64바이트 메모리를 캐시에 가져오는 과정에서 sdshdr 또한 같이 가져온다. 즉, CPU는 메모리에 다시 갈 필요 없이 즉시 데이터를 처리한다(캐시 히트).
다만, embstr 는 수정이 불가능하다. 만약 문자열 뒤에 다른 문자열을 추가한다면, 공간이 부족하므로 다른 곳으로 이동시켜야 한다. 이러한 재할당 과정은 복잡하므로 레디스는 이러한 과정을 구현하지 않기로 결정하였다. 따라서 만약 embstr로 저장된 데이터를 수정하면 레디스는 이를 raw 인코딩으로 변환한 후 수정한다. 이후 embstr 로 변환될 수 있는 크기가 되어도 다시 embstr로 돌아가지 않는다.
raw
raw 는 44바이트를 초과하는 문자열일 때 사용하는 방식이다. 데이터를 저장할 때 OS에 메모리를 두 번 요청한다. 하나는 redisObject, 하나는 sdshdr 을 만든다. 이후 ptr 변수는 sdshdr 의 주소를 가리키게 된다.
raw 방식은 확장성이 좋다. 만약 문자열 뒤에 문자열을 붙여 크기가 늘어났다고 가정하자. embstr 이라면 블록 전체를 더 큰 공간에 할당시켜야 한다. 그러나 raw 는 sdshdr 만 넓은 공간으로 이동시키면 된다. 이후 ptr 주소만 바꿔주면 된다.
또한 대용량 데이터를 저장하기 위해 연속된 거대한 메모리 공간이 필요한데, 여기에 redisObject 까지 붙게 된다면 OS 입장에서 적당한 메모리 공간을 찾기 더 까다로울 수 있다.
다만, 성능 상의 단점이 존재한다. redisObject 헤더와 sdshdr 헤더가 별도로 존재하므로 메모리를 조금 더 사용하게 된다. 또한 작은 메모리 조각이 흩어지게 되어 embstr 보다 파편화가 발생할 확률이 높다.
그리고 캐시 미스 문제가 있다. CPU가 redisObject 를 읽고 ptr을 따라갔으나 데이터가 캐시에 없는 경우, CPU는 메모리에서 데이터를 가져와야 한다. 이때 발생하는 CPU 중단으로 발생하는 비용을 pointer chasing 이라고 한다.
명령어
SET
SET key value 는 key에 value를 저장하는 명령이다. 이미 존재하는 key라면 기존 데이터를 덮어쓴다. 또한 기존 key에 TTL이 설정되어 있었다면 수행 후 TTL이 사라지고 영구 저장 상태가 된다.
TTL을 설정하기 위한 옵션은 EX 와 PX 가 있다.
EX sec 은 초 단위로, PX ms 는 밀리세컨즈 단위로 TTL을 설정한다.
또한 데이터의 존재 여부에 따라 저장을 할지, 말지 결정할 수 있다.
NX 은 키가 없을 때만 저장하고, XX 는 키가 이미 있을 때 덮어쓰도록 하는 옵션이다.
명령이 성공하면 OK 문자열을 반환하며, 실패하면 nil을 반환한다.
레디스는 해시 테이블 구조이므로 SET 명령의 시간복잡도는 $O(1)$이다.
분산 락을 구현할 때 SET 명령을 사용할 수 있다. 단일 서버라면 Mutex 등을 사용하면 되지만, 서버가 여러 대인 분산 환경에서는 레디스를 사용한 분산 락 방법을 많이 사용한다.
SET lock:product "user_1" NX EX 10
lock:product 는 락 이름이다. NX 는 락이 없을 때만 점유하도록 하며, 서버가 다운되었을 때 락을 계속 점유하여 데드락이 발생하는 것을 막기 위해 TTL을 설정한다.
락 획득에 성공하면 재고를 차감시키고 마지막에 DEL 로 락을 삭제한다.
만약 nil 이 반환된다면 이미 다른 사람이 구매 중인 것이다(== 다른 사람이 락을 점유 중임).
레디스로 멱등성을 보장할 수 있다. 사용자가 결제 버튼을 더블 클릭하거나, 네트워크 오류 등으로 요청이 두 번 전송되었을 때 시스템이 이를 한 번만 처리하도록 하는 것이다.
사용자가 결제 요청을 보내면, 요청 ID(req_abc)를 key로 하여 NX 를 사용하여 레디스에 저장한다.
SET req_abc "processing" NX EX 30
위 명령의 반환값이 OK 라면 처음 온 요청이다. 따라서 결제를 진행한다. 만약 nil이라면 이미 처리 중인 요청이다.
레디스로 API 디바운싱을 구현할 수 있다. API 디바운싱이란 너무 잦은 API 호출을 방지하는 기법이다.
특정 API는 유저 당 5초에 한 번만 요청할 수 있도록 구현하고 싶다. 레디스에 유저 ID를 key로 하고, NX와 EX를 사용한다.
SET user:100 "1" NX EX 5
만약 반환값이 OK 라면 요청을 허용한다. 이후 5초 동안은 NX 옵션 때문에 같은 명령을 시도해도 실패한다.
레디스 6.2부터 추가된 GET 옵션을 사용하면 값을 덮어쓰면서 덮어쓰기 전의 값을 구할 수 있다. 이를 통해 데이터가 어떻게 변했는지 추적할 수 있다.
예를 들어 IoT 센서가 온도를 계속 보내는데, 이전 온도와 현재 온도를 비교해서 5도 이상 변했으면 경고를 보내려고 한다.
SET sensor:temp "25" GET
이전에 들어 있던 값은 20이라고 하자. 레디스는 25라는 값을 넣고, 이전 값인 20을 반환한다.
애플리케이션은 반환받은 20과 현재 보낸 25를 비교하여 경고를 발송한다.
SET 명령은 매우 빠르나, 실제 성능은 RTT에 달려 있다. 클라이언트가 명령을 보내면 네트워크를 타고 레디스 서버로 간다. 이후 레디스가 메모리에 명령을 수행하고 응답이 다시 네트워크를 타고 돌아온다. 이 과정에서 걸린 시간은 네트워크를 통해 이동한 시간이 대부분을 차지한다.
여러 개의 key-value 쌍을 한 번의 요청으로 저장하기 위해 MSET 명령을 사용한다.
MSET
MSET 은 여러 개의 key-value 쌍을 한 번의 요청을 저장하는 명령이다.
MSET key1 value1 key2 value2 ...
시간복잡도는 $O(N)$이다.
MSET 명령 또한 원자적이다. MSET 명령이 키를 저장하는 도중에 다른 클라이언트가 키를 조회하거나 수정할 수 없다.
만약 SET 명령을 N번 반복한다면, value를 저장하는 간격 사이에 다른 클라이언트가 데이터를 읽거나 변경할 수 있는 문제가 있다.
레디스는 싱글 쓰레드이기 때문에, 다량의 key-value 쌍을 MSET 명령을 통해 보내는 것은 위험할 수 있다. 메모리에 쓰는 시간이 오래 걸릴 수 있고, 그 시간 동안 다른 모든 요청은 멈추게 되기 때문이다. 따라서 다량의 데이터를 넣는 경우, chunking해서 여러 번 MSET 명령을 호출하는 것이 안전하고 빠르다.
SETNX
SETNX 은 키가 존재하지 않을 때 값을 저장하는 명령이다. 이미 키가 있다면 아무 작업을 수행하지 않는다. SET 명령과 NX 옵션을 결합한 것이다.
SETNX key value
만약 저장에 성공하면 1, 실패하면 0을 리턴한다.
이전에 살펴본 바와 같이, 당연히 SETNX 을 통해 동시성 제어를 할 수 있다. 그러나 SETNX 을 통해 분산 락을 구현하면 데드락 문제가 발생할 수 있다.
락을 걸었으면 언젠가는 락을 풀어야 하는데, 락을 건 순간 서버가 다운되면 데드락 문제가 발생한다. 이를 막기 위해 TTL을 설정해야 하는데, SETNX 명령 자체에는 TTL을 설정하는 옵션이 없다.
따라서 SET 명령의 NX, EX 옵션을 사용하여 분산 락을 구현하는 것이 일반적인 방법이다.
GET
GET key 는 key에 저장된 value를 반환하는 명령이다.
GET 명령을 실행했을 때 발생할 수 있는 결과는 크게 3가지이다.
- key가 존재하고 value가 String 타입일 때, 저장된 문자열 값을 그대로 반환한다.
- key가 존재하지 않을 때
nil을 반환한다. - key는 존재하지만 value의 타입이 String이 아닐 때 에러 메시지를 반환한다.
GET 명령 역시 시간복잡도는 $O(1)$이다. GET 명령 자체는 매우 빠르지만, 실제 성능은 RTT에 좌우된다. 따라서 여러 개의 key를 한 번에 조회할 때는 GET 명령을 여러 번 수행하는 것이 아니라 MGET 명령을 사용해야 한다.
MGET
MGET 명령은 여러 개의 key에 대한 value를 한 번의 요청을 조회하는 명령이다.
MGET key1 key2 key3 ...
역시 시간복잡도는 $O(N)$이다.
만약 조회하려고 하는 key들 중 일부 key에 대한 value가 없다면 해당 key에 대해서 nil 을 반환한다. 즉, 부분 실패가 없다.
MGET 이 반환하는 리스트의 순서는 key의 순서와 일치한다.
GETSET
GETSET 명령은 조회와 저장을 동시에 수행하는 명령이다.
GETSET key new_value
키에 new_value 를 저장하고 저장하기 직전의 old_value 를 리턴한다.
GETSET 명령은 원자적이기 때문에, GET 과 SET 명령을 따로 수행하여 발생할 수 있는 race condition 문제를 방지할 수 있다.
다만, SET 명령에 GET 옵션이 추가되면서 GETSET 은 공식적으로 deprecated 되었다.
DEL
DEL 명령은 key와 그와 연결된 value를 삭제하는 명령이다.
DEL key [key ...]
하나 이상의 key를 삭제한다. 만약 key가 존재하지 않으면 무시한다. 반환값은 실제로 삭제된 key의 개수이다.
1
2
3
4
5
6
7
8
9
10
> SET key1 "Hello"
OK
> SET key2 "World"
OK
> DEL key1
(integer) 1
> DEL key2 key3
(integer) 1
String 타입에서 DEL 명령의 시간복잡도는 $O(N)$이다. $N$은 삭제하려고 하는 key의 개수이다.
레디스는 싱글 쓰레드이며, DEL 명령은 동기 방식으로 동작한다. 만약 대량의 key를 삭제하는 경우 오랜 시간이 걸리게 되며, 그 시간 동안 다른 요청은 대기 상태에 빠진다. 실제 운영 환경에서 크기가 큰 key를 무작정 DEL 로 지우면 장애가 발생할 수 있다.
이를 방지하기 위해 UNLINK 명령을 사용한다.
UNLINK key [key ...]
UNLINK 명령은 비동기적으로 키를 삭제한다. 실제 거대한 데이터를 메모리에서 지우는 작업은 별도의 백그라운드 쓰레드에서 작업한다.
INCR
String 타입이지만 산술 연산이 가능하다.
INCR key
key에 저장된 숫자를 1 증가시키고, 증가된 값을 반환한다. 시간복잡도는 $O(1)$이다.
key가 존재하지 않아도 동작한다. 레디스를 값을 0으로 초기화한 후 1을 더한 후, 1을 리턴한다. 즉, 초기값을 SET 으로 따로 잡지 않고 바로 INCR 를 수행해도 된다.
먼저 저장된 value를 가져와, 숫자로 바꿀 수 있는지 확인한다. 만약 바꿀 수 있다면 변환된 값에 1을 더한다.
참고로 64비트 signed integer 범위 내에서 이루어진다.
이후 결과를 다시 문자열로 변환하여 저장한다.
왜 굳이 GET 으로 값을 읽어 1을 증가시키고, SET 으로 저장하지 않는 것일까? INCR 의 원자성 때문이다.
1
2
3
val = redis.get("count") # value는 10
val = int(val) + 1
redis.set("count", val)
3명의 사용자가 위 작업을 동시에 수행하면 어떤 일이 벌어질까? 여러 사용자가 모두 10을 읽어 11을 저장하므로 결과가 11이 될 것이다. 우리가 원하는 결과는 13이다.
INCR 명령을 사용하게 되면 3명의 사용자가 동시에 수행해도 정확히 13으로 저장된다.
보통 INCR 명령을 조회수 카운터나 좋아요 기능에 사용한다.
INCR 명령은 숫자로 변환할 수 없는 문자열에 대해서는 에러가 발생한다.
또한 오버플로우가 발생하는 경우도 에러를 반환한다.
RDB의 AUTO_INCREMENT 기능을 레디스로 대체할 수 있다. DB 샤딩을 통해 여러 DB를 쓸 때, 전역적으로 유일한 ID를 만들어야 한다면 레디스의 INCR 를 사용해야 한다.
사용자 주문에 대한 DB가 존재한다고 하자. 샤딩으로 DB를 세 대(A, B, C)로 쪼갰다.
사용자 1, 사용자 2가 주문을 넣는다. 사용자 1에 대한 주문은 로드밸런서에 의해 A로, 사용자 2에 대한 주문은 B로 전달되었다. 각 주문은 DB 입장에서 첫 주문이니 모드 ID가 1이 된다. 사실은 다른 주문이다!
나중에 ID가 1인 주문을 가져오려고 시도하면, 주문 2개가 나오게 된다. 이를 PK 충돌이라고 한다.
이 문제를 해결하기 위해 DB가 각자 번호를 매기도록 하지 말고, 외부의 레디스가 번호를 매겨주어야 한다. 레디스가 은행 번호표 역할을 한다고 생각하면 된다.
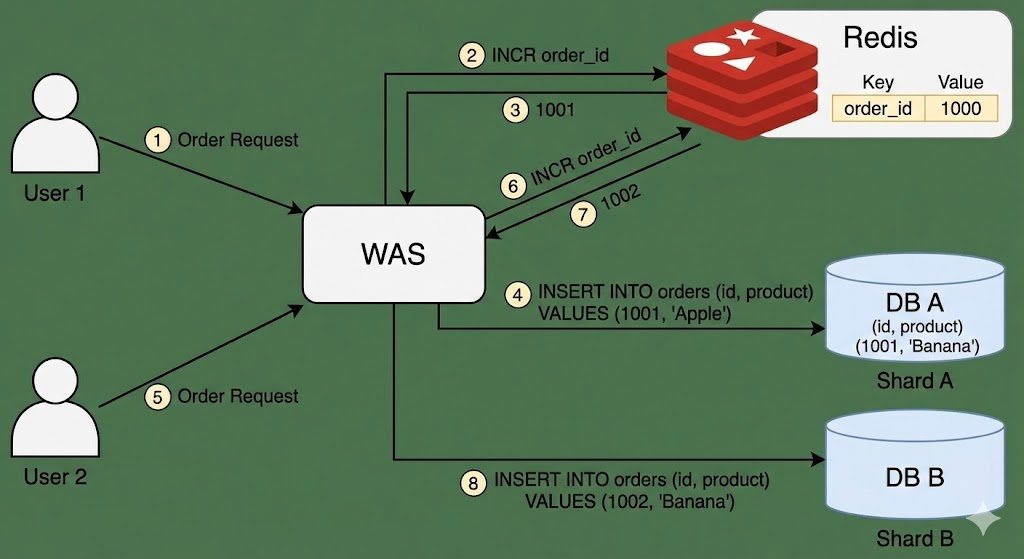
번호표 역할을 하는 key가 order_id 라고 하자. 사용자 1이 주문을 하면, WAS는 DB에 바로 넣는 게 아니라 먼저 레디스에 접근하여, INCR order_id 명령을 수행한다. 이후 WAS는 리턴된 값(번호표)를 가지고 A에 접근하여 데이터를 삽입한다(INSERT INTO orders (id, product) VALUES (1001, 'Apple')). 이후 사용자 2가 주문을 하면 레디스는 다른 번호를 발급하고, B에 데이터를 삽입한다(INSERT INTO orders (id, product) VALUES (1002, 'Banana')).
레디스 대신 UUID를 사용하는 방법을 생각할 수도 있다. 물론 UUID를 사용하면 중복을 피할 수는 있다. 그러나 길이가 길고 무작위이기 때문에 DB 인덱스 성능이 떨어지게 된다.
RDB의 B+ Tree 인덱스 구조를 생각해보면 된다.
API 호출 제한에도 INCR 를 사용할 수 있다. 아이디어는 단순하다. 특정 IP가 API를 호출하면 value를 1 증가시킨다. 만약 특정 임계값을 넘으면 막는다. 특정 시간 이후 만료되도록 설정하면 된다.
INCR rate:limit:192.168.0.1
첫 번째 요청이 들어오면 해당 key의 값이 1로 설정된다. 이후 EXPIRE 명령을 통해 TTL을 설정한다.
만약 임계값이 10이고, INCR 명령의 리턴값이 11이라면 429 Too Many Request 를 응답으로 넘겨준다.
다만, 위 방법은 INCR는 성공했으나 EXPIRE 을 설정하기 직전에 서버가 다운되는 문제를 해결하지 못한다. 이를 막기 위해 INCR 와 EXPIRE 을 한 번에 묶어서 실행하는 lua script를 사용하면 된다.
INCRBY
INCRBY 는 INCR 와 다르게, 사용자가 지정한 정수만큼 증가시키는 명령이다.
INCRBY key increment
key에 저장된 숫자에 increment 을 더한다. 시간복잡도는 $O(1)$이고, 리턴값은 연산이 완료된 후의 최종 값이다.
INCR 와 마찬가지로 키가 존재하지 않으면 0으로 초기화한 후 연산을 진행한다.
또한 음수를 넣어 뺄셈을 할 수도 있다.
INCRBY 역시 원자적이다.
레디스를 번호표 역할로 사용할 때, 만약 트래픽이 초 당 수만 건이라면, INCR 의 RTT 시간이 문제가 될 수 있다. 이 경우 번호를 묶음으로 가져오는 전략을 사용한다.
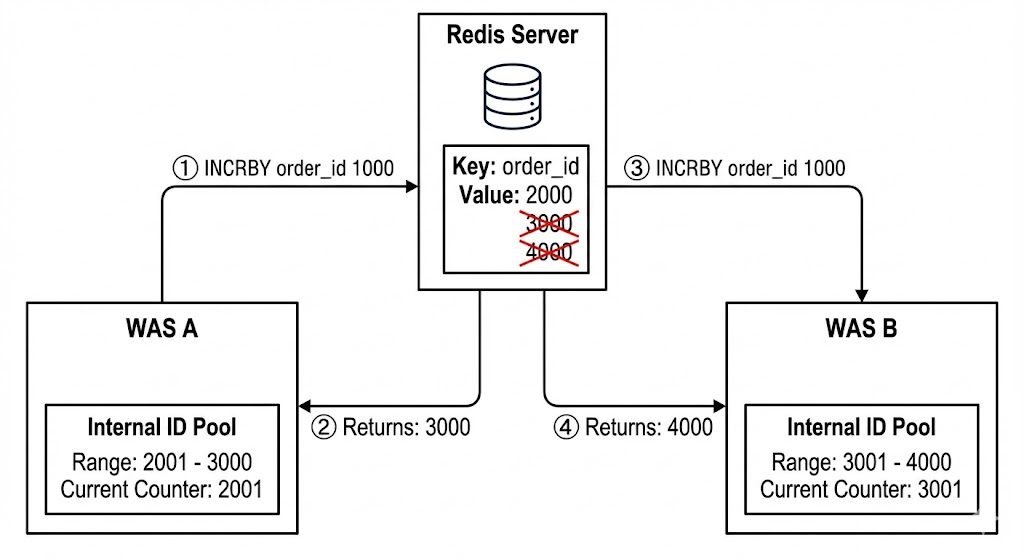
WAS A가 레디스에서 번호표 1000개를 미리 받는다. 레디스는 INCRBY order_id 1000 를 실행한다. 이후 WAS A는 내부 변수에서 2001번부터 3000번까지 번호를 할당한다.
WAS B 또한 번호표를 1000개를 미리 받고, 3001번부터 4000번까지 번호를 할당한다.
위와 같은 방식은 레디스와의 통신 횟수를 줄이면서, 중복 없이 번호를 할당할 수 있다.
비슷한 예시로, 조회수 카운팅 시에도 매번 INCR 명령을 보내는 것은 네트워크 부하가 있을 수 있으므로, WAS 메모리에 잠시 모았다가 한 번에 반영할 때 INCRBY 명령을 사용한다.
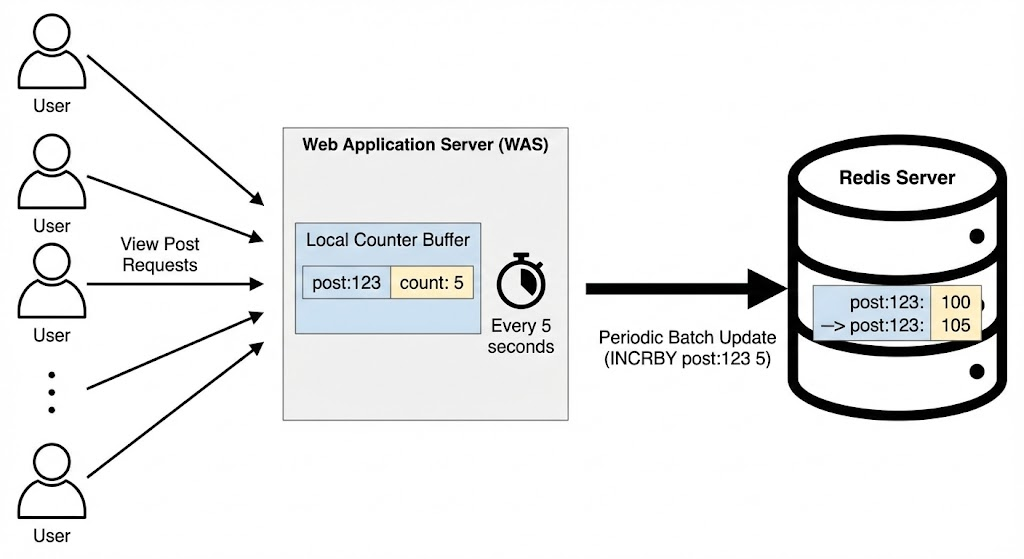
사용자가 게시글을 조회할 때마다 레디스에게 조회수 증가 명령을 보내지 않고, 로컬 변수에 카운터 값을 1 증가시킨다. 이후 특정 주기마다 INCRBY 를 통해 조회수를 증가시킨다.
다만, 이러한 벌크 할당 및 업데이트는 WAS가 다운되면 내부적으로 유지하고 있던 데이터가 유실된다는 문제가 있다.
DECR
DECR 명령은 INCR 명령과 반대로 키에 저장된 정수 값을 1 감소시키는 명령이다.
DECR key
key에 저장된 숫자를 1 감소시키고 감소된 최종 값을 리턴한다. 시간복잡도는 $O(1)$이다.
역시 key가 존재하지 않으면 레디스는 값을 0으로 초기화한 후 1을 뺀다.
DECRBY
INCRBY 와 마찬가지로, 원하는 정수만큼 감소시키는 DECRBY 명령이 존재한다.
DECRBY key decrement