Redis의 자료형과 명령어 - List
Redis의 자료형과 명령어 - List
List
List 자료형은 레디스를 메시지 큐나 스택, 대기열로 사용할 수 있게 하는 자료구조이다. 이름은 List 이지만 배열이 아니라 연결 리스트이다.
파이썬의 list나 자바의 ArrayList 는 배열이다. 배열은 인덱스로 접근하는 것은 빠르지만($O(1)$), 데이터를 삽입하는 작업은 느리다($O(N)$). 모든 데이터를 한 칸씩 밀어야 하기 때문이다.
연결 리스트는 head, tail에 삽입 및 삭제하는 속도는 $O(1)$이다. 다만 인덱스를 통한 접근은 $O(N)$로 느리다. 따라서 레디스 리스트를 배열의 원소를 탐색하는 용도로 사용하면 느리다.
초기에는 데이터가 적으면 ZipList, 많으면 LinkedList 를 사용했다.
ZipList 는 메모리 효율을 극대화하기 위해 데이터를 압축하여 저장하는 연결 리스트이다. 일반적인 연결 리스트와 달리 데이터들을 연속된 하나의 메모리 블록에 순차적으로 저장한다. 각 데이터 노드는 포인터를 가지지 않는 대신 자신의 길이 정보와 이전 노드의 길이 정보를 자체적으로 가지고 있어 리스트 순회가 가능하다. 이러한 구조 덕분에 포인터 메모리 오버헤드가 없으며, 데이터가 모여 있어 CPU 캐시 효율이 높다는 장점이 있었다.
그러나 LinkedList는 일단 데이터 하나하나가 별도의 노드 객체이다. 또한 앞뒤 노드를 연결하는 포인터까지 사용하므로 메모리 낭비가 발생했다. 또한 노드들이 메모리 여기저기 흩어져 있으므로 파편화가 발생했고, CPU 캐시 효율이 떨어졌다.
또한 ZipList 는 중간에 데이터를 넣거나 빼기 위해 안에 존재하는 원소들을 재배치 해야 했다. 이 작업은 $O(N)$ 이 걸리므로, 길이가 긴 경우 문제가 발생했다.
레디스 3.2부터 이 둘을 합친 QuickList 라는 독자적인 구조를 사용한다. QuickList 는 ZipList 의 연결 리스트 형태이다. QuickList 의 노드 안에는 여러 개의 데이터가 채워진 ZipList가 들어있다. 즉, 전체적으로는 연결 리스트 형태를 띄고 있어 노드 삽입 및 삭제가 빠르며, 노드 내부는 ZipList로 구성되어 포인터 오버헤드를 없애고 메모리 효율을 높인다.
Redis 7.0 이상 버전에서는 QuickList 노드의 데이터 타입이 ZipList에서 ListPack으로 대체되었다(인코딩 이름은 그대로 quicklist이다).
ZipList가 저장하는 이전 노드의 길이 정보(prevlen)은 가변적이다. 데이터 길이가 254바이트 미만이면 prevlen은 1바이트만 차지하며, 254바이트 이상이면 5바이트로 늘어난다.
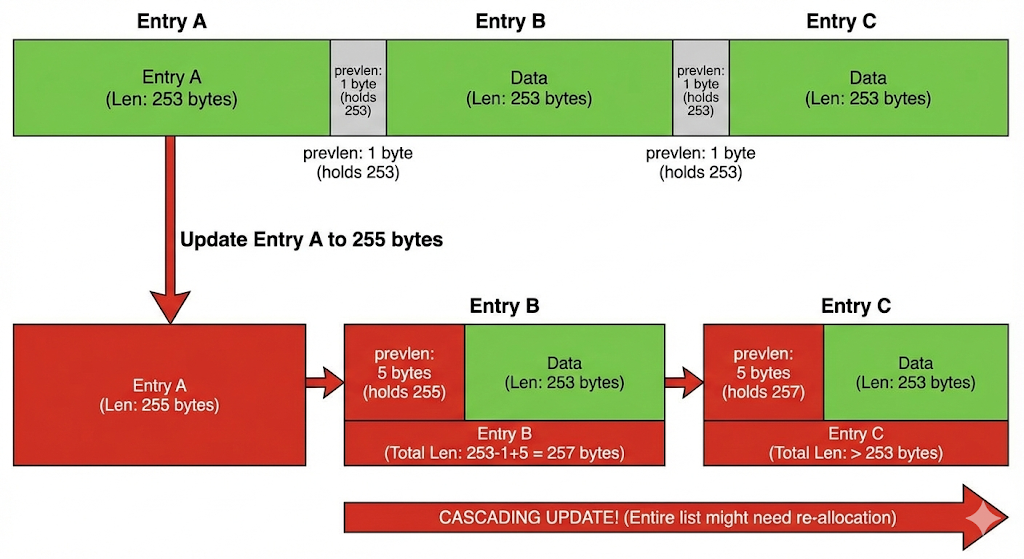
ZipList에 253바이트의 데이터들이 연속으로 들어있는 상황을 생각해보자. 노드 A의 데이터를 수정하여 255바이트가 되었다고 하자. 그럼 노드 B의 prevlen을 5바이트로 늘려야 하는데, 이 과정에서 노드 B 또한 255바이트를 넘기게 된다. 이 과정이 연쇄적으로 일어난다면, 데이터 하나만 수정했는데 전체 리스트를 수정해야 하는 문제가 발생한다.
ListPack은 ZipList와 유사하나, 길이 정보를 저장하는 위치만 변경하였다. ZipList는 길이 정보를 header에 저장했으나, ListPack은 본인의 길이를 tail에 저장하였다. 이를 통해 본인 노드의 데이터 길이 변화가 다른 노드에 영향을 주지 않는다.
그렇다면 순회는 어떻게 진행할까? ListPack을 사용하면 현재 위치의 바로 왼쪽 바이트가 이전 노드의 tail이 되므로, 이를 통해 순회한다.
String 은 데이터 크기에 따라 인코딩이 int, embstr, raw로 변하지만 Redis 3.2 이상의 List는 quicklist 라는 하나의 인코딩으로 사용된다.
명령어
LPUSH, RPUSH
LPUSH key value [value ...]
RPUSH key value [value ...]
LPUSH와 RPUSH는 List에 데이터를 삽입하는 명령이다. List는 double linked list이므로 왼쪽, 오른쪽 어디든 데이터를 $O(1)$에 넣을 수 있다.
명령 수행 후 리스트의 전체 길이를 리턴한다.
LPUSH와 RPUSH 모두 한 번에 여러 개의 데이터를 삽입할 수 있는데, 이때 데이터가 들어가는 순서를 헷갈리면 안 된다.
1
2
3
4
5
> RPUSH mylist "A" "B" "C"
# 결과: [A, B, C]
> LPUSH mylist "A" "B" "C"
# 결과: [C, B, A]
RPUSH는 직관적이나, LPUSH는 그렇지 않으니 주의해야 한다.
LPOP, RPOP
LPOP key [count]
RPOP key [count]
LPOP, RPOP은 List에서 데이터를 삭제하는 명령이다. 리턴값은 꺼낸 데이터이며, 리스트가 비어있거나 키가 없다면 nil을 리턴한다.
count옵션은 Redis 6.2부터 지원한다.
PUSH와 POP 명령을 어떻게 쓰느냐에 따라 List는 다양하게 사용될 수 있다.
메시지 큐
List가 큐(FIFO)처럼 동작하기 위해 producer는 RPUSH로 데이터를 삽입하고 consumer는 LPOP으로 데이터를 꺼낸다.
실무에서는 LPOP 대신 BLPOP을 사용하여 큐가 비었을 경우 불필요하게 조회하지 않고 대기하도록 구현한다. LPOP은 큐에 데이터가 없을 경우 즉시 nil을 리턴하고 끝나기 때문에, consumer는 polling 방식으로 데이터가 존재하는지 계속 확인해야 한다. 불필요하게 Redis CPU와 네트워크 대역폭을 사용하게 된다.
1
2
> BLPOP myqueue [timeout]
# timeout이 0이면 무한히 대기
이를 방지하기 위한 BLPOP은 큐가 비어있다면 데이터가 들어올 때까지 연결을 끊지 않고 기다리는 명령이다.
다만 블로킹 상태의 클라이언트는 Redis와의 연결을 하나 계속 점유하므로, consumer가 수천 개라면 Redis의 maxclients 설정을 확인해야 한다.
만약 여러 클라이언트가 동시에 같은 키에 대해 BLPOP으로 대기 중이라면, Redis는 먼저 대기한 클라이언트에게 데이터를 먼저 전달한다.
스택
실무에서 스택(LIFO)은 브라우저의 뒤로 가기, 최근 본 상품 등에 사용된다. LPUSH로 데이터를 넣고 LPOP으로 데이터를 꺼내면 된다.
만약 List를 스택으로 활용하여 최근 본 상품을 구현했을 때, 똑같은 상품을 여러 번 봤을 때 발생하는 중복 현상은 어떻게 방지해야 할까? List의 중복을 제거하는 명령인 LREM을 사용하면 된다.
LREM 명령에 대한 설명은 후술한다.
순환 리스트, Reliable Queue
List에서 데이터를 꺼내 처리하다 서버가 다운되면 해당 데이터는 유실되게 된다. 이를 방지하게 위해 꺼냄과 동시에 다른 리스트에 넣는 명령이 존재한다.
RPOPLPUSH source destination
RPOPLPUSH(또는 LMOVE)은 리스트에서 데이터를 꺼내는 동작과 다른 리스트에 넣는 동작을 하나의 원자적 명령으로 묶은 것이다. source 리스트에서 데이터를 꺼내고(RPOP), 꺼낸 데이터를 destination 리스트에 넣고(LPUSH) 클라이언트에 해당 데이터를 리턴한다.
LREM
LREM key count value
LREM 은 리스트에서 특정 값과 일치하는 원소를 찾아 삭제하는 명령이다. count 는 삭제할 개수와 방향을 결정하는 파라미터이다.
만약 count가 양수라면 앞에서부터 N개를 삭제한다. 음수라면 뒤에서부터 N개를 삭제하며, 0이라면 일치하는 모든 value를 삭제한다.
시간복잡도는 $O(N+M)$이며, $N$은 리스트의 길이, $M$은 실제로 삭제된 원소 개수이다.
LLEN
LLEN key
LLEN은 리스트에 저장된 원소의 개수를 리턴하는 명령이다.
QuickList 헤더에 리스트의 전체 길이를 저장하는 count 변수가 있기 때문에, $O(1)$에 리스트 길이 정보를 가져올 수 있다.
LRANGE
LRANGE key start stop
LRANGE 는 리스트의 특정 범위에 있는 원소들을 조회하는 명령이다. start부터 stop까지 원소를 포함하여 결과를 리턴한다.
시간복잡도는 $O(S+N)$이다. 이때 $S$는 start까지 이동하는 오프셋 거리이며, $N$은 조회하려고 하는 원소의 개수이다. $S$가 너무 크다면 순회하는데 CPU 자원을 많이 소모할 수 있다.
Redis List는 0-based index와 -1부터 시작하는 역방향 인덱스 모두 지원한다.
start나 stop을 잘못 설정하여도 에러를 발생하지 않고 알아서 처리한다.
예를 들어 리스트 길이는 5이나 LRANGE key 0 100을 수행하는 경우 실제 존재하는 5개만 리턴한다.
또한 LRANGE key 5 2와 같이 start가 stop보다 큰 경우 빈 리스트를 리턴한다.
LINDEX
LINDEX key index
LINDEX 는 리스트의 특정 인덱스에 있는 데이터를 조회하는 명령이다. 인덱스의 범위가 벗어나거나 키가 없다면 nil을 리턴한다. 역시 양방향 인덱스(양수, 음수 인덱스)를 모두 지원한다.
시간복잡도는 $O(N)$이다. 이때 $N$은 인덱스까지 도달하기 위해 지나야 하는 노드의 수이다. C 또는 Java의 배열에서 특정 인덱스에 접근하는 속도가 $O(1)$에 비하면 느린 속도이다. Redis의 List는 연결 리스트이기 때문에 특정 인덱스에 접근하는 연산의 속도는 느리다.
따라서 LINDEX는 리스트의 첫 번째 또는 마지막 값을 확인하고 싶을 때, 리스트의 크기가 작을 때 사용하는 것이 좋으며, 대용량 크기 리스트의 랜덤 액세스에는 권장하지 않는다.
LTRIM
LTRIM key start stop
LTRIM 명령은 리스트에서 지정한 범위 내 속한 원소는 남기고 나머지는 모두 삭제하는 명령이다.
start부터 stop 인덱스까지의 데이터만 남기고 범위 밖의 데이터는 영구적으로 삭제한다. 시간복잡도는 $O(N)$으로, $N$은 삭제되는 원소의 개수이다.
LTRIM은 보통 데이터의 개수를 일정하게 유지하는 데 사용한다. List를 로그를 기록하는 데 사용하는 경우 리스트가 무한히 커질 수 있다. 따라서 최신 N개만 유지하고 싶은 경우 LTRIM을 사용한다.