Redis의 자료형과 명령어 - Set
Redis의 자료형과 명령어 - Set
Set
Redis의 Set은 자바의 HashSet이나 파이썬의 set과 거의 유사하게 동작한다. 즉, 순서가 없고 중복을 허용하지 않는 문자열들의 집합이다.
같은 데이터를 여러 번 삽입하여도 한 번만 저장되며, 데이터를 넣은 순서를 보장하지 않는다(unordered), 또한 내부적으로 해시 테이블로 구현되어 있기 때문에 데이터의 존재 여부를 확인하는 명령이 $O(1)$로 빠르다.
보통 해시 테이블은 key와 value가 일대일로 매핑되는 구조이다. 그러나 Redis의 Set은 value를 더미 또는 NULL로 처리한다. 단순히 데이터가 존재하는지 확인하기 위함이므로 굳이 value가 필요없는 것이다.
물론 다른 프로그래밍 언어에서도 Set은 위와 같은 구조로 구현되어 있다.
인코딩 방식
intset
1
2
3
4
5
typedef struct intset {
uint32_t encoding; // 데이터 크기
uint32_t length; // 데이터 개수
int8_t contents[]; // 실제 숫자가 들어가는 배열
} intset;
모든 원소가 정수이고 개수가 설정값(기본값 512개) 이하일 때 intset 방식으로 인코딩한다.
linked list와 hash table은 데이터들을 연결하기 위해 포인터가 필요하다. 그러나 intset 은 C언어의 배열과 유사하게 메모리 공간에 숫자가 오름차순으로 배치된다.
정렬되어 있다는 것은 이진 탐색이 가능하다는 의미이다. 따라서 검색 시간이 $O(1)$이 아니라 $O(logN)$이다. 메모리 효율을 위해 속도를 희생한 것이다.
정렬되어 숫자가 저장되어야 하므로 삽입 시 발생하는 시간복잡도는 $O(N)$이다.
intset 은 가변 인코딩 방식을 사용한다.
encoding 이 INTSET_ENC_INT16 은 모든 숫자가 -32768 ~ 32767 범위 내에 속할 때 사용한다. 숫자 하나당 2바이트를 사용한다.
INTSET_ENC_INT32 는 범위를 벗어나는 숫자가 하나라도 들어오면 전체 배열을 4바이트 단위로 재할당한다.
INTSET_ENC_INT64 는 21억을 넘는 숫자가 들어오면 8바이트 단위로 재할당한다.
이때 한 번 변경된 바이트 크기는 다시 줄일 수 없다.
hashtable
원소 중 하나라도 문자열이거나 개수가 설정값을 초과할 때 hashtable 인코딩 방식을 사용한다.
내부적으로 Redis의 dict 자료구조를 사용한다. 위에서 설명한 바와 같이 key에는 Set의 실제 데이터, value에는 NULL을 저장한다.
intset에서 hashtable로 한 번 변환되면 다시 반대로의 변환은 불가능하다.
검색, 삭제, 추가 작업 모두 $O(1)$의 시간복잡도를 가진다.
listpack
Redis 7.2부터 도입된 listpack은 hashtable의 과도한 오버헤드를 방지하기 위해 도입되었다. 데이터들을 연속된 메모리 공간에 저장하며, 개수가 적은 문자열 집합(기본값 128개, 64바이트 이하)에 대하여 사용한다.
명령어
SADD
SADD key member [member ...]
SADD 는 key에 해당하는 집합에 member를 추가하는 명령이다. 시간복잡도는 $O(N)$으로, $N$은 추가하려고 하는 member의 수이다. 리턴값은 실제로 새로 추가된 원소의 개수이다. 이미 존재하는 데이터는 카운트에서 제외된다.
이러한 성질로 인해 추가하려는 데이터가 처음 들어온 것인지, 원래 있던 것인지 판단할 수 있다.
Redis 내부적으로 해당 key의 Set 내부를 검색하여 추가하려는 값이 이미 있는지 확인한다. 값이 정수이고 intset 상태라면 intset에 추가하고, 값이 문자열이거나 intset 용량이 찬 경우 hashtable로 변환 후 추가한다. 중복된 데이터가 아니라면 메모리에 데이터를 쓰고 count를 1 증가시킨다.
SREM
SREM key member [member ...]
SREM 은 key에 해당하는 집합에 member를 제거하는 명령이다. 시간복잡도는 $O(N)$으로, $N$은 제거하려고 하는 member의 수이다. 리턴값은 실제로 제거된 원소의 개수이다. 역시 존재하지 않은 데이터는 카운트에서 제외된다.
SISMEMBER
SISMEMBER key member
SISMEMBER 은 key에 저장된 집합이 member에 존재하는지 확인하는 명령이다. intset 인코딩인 경우 이전 탐색을 사용하므로 $O(logN)$이지만, 그렇지 않은 경우 $O(1)$이다. 다만, $N$이 작기 때문에 CPU 입장에서는 $O(1)$이나 다름없다.
리턴값은 존재하는 경우 1, 그렇지 않은 경우 0이다.
SMISMEMBER key member [member ...]
Redis 6.2부터 한 번의 명령으로 여러 개의 원소 존재 여부를 확인하는 SMISMEMBER 명령을 지원한다. SISMEMBER 를 반복하면 RTT로 인해 네트워크 오버헤드가 발생하므로, 한 번의 명령으로 원소들의 존재 유무를 리턴한다.
리턴되는 1과 0의 리스트는 요청한 원소의 순서와 일치한다.
SCARD
SCARD key
SCARD는 집합에 들어있는 전체 원소의 개수를 리턴하는 명령이다. key가 존재하지 않은 경우 0을 리턴한다.
Redis의 intset 또는 hashtable의 헤더에 집합의 개수를 저장하는 변수를 두고 있기 때문에 시간복잡도는 $O(1)$이다.
SMEMBERS
SMEMBERS key
SMEMBERS 는 Set에 저장된 모든 원소들을 리스트 형태로 리턴한다. 시간복잡도는 $O(N)$이다. 키가 없거나 집합이 비어있다면 빈 리스트를 리턴한다.
리턴된 결과는 순서를 보장하지 않는다. 내부적으로 해시 테이블을 사용하기 때문.
시간복잡도가 $O(N)$이므로 데이터가 많은 경우 다른 요청은 실행되지 못하고 대기하는 블로킹 현상이 발생할 수 있다($\because$ Redis는 싱글 쓰레드)
SSCAN
SSCAN key cursor [MATCH pattern] [COUNT count]
SSCAN 은 Set에 있는 원소들을 커서 기반으로 나누어 조회하는 명령이다. SMEMBERS는 레디스 서버가 블로킹될 수 있는 문제가 있었다. 대량의 데이터를 효율적으로 조회하기 위해 SSCAN을 사용해야 한다.
cursor는 순회의 시작 위치이다. 처음 시작하는 경우 0을 넣는다. MATCH 옵션을 통해 특정 패턴에 맞는 key만 필터링할 수 있으며, COUNT 옵션을 통해 한 번에 몇 개를 가져올지 지정할 수 있다.
1
2
3
4
5
6
127.0.0.1:6379> SSCAN myset 0 COUNT 3
1) "3"
2) 1) "1"
3) "5"
4) "8"
5) "2"
SSCAN은 한 번에 모든 데이터를 클라이언트에게 주지 않는다. 커서(다음 페이지 번호)와 데이터의 일부를 준다.
COUNT 옵션은 힌트이다. COUNT 10이 정확히 10개의 원소가 담긴 리스트를 리턴하지 않는다는 것이다.
이유는 Redis의 해시 테이블의 구조적 특성에 있다. COUNT는 리턴할 데이터의 수가 아니라 해시 테이블의 버킷의 검사 횟수이다.
hashtable 인코딩을 사용하는 경우 Set은 거대한 배열인 버킷들로 구성되게 된다. 각 버킷은 특정 해시 값을 가진 데이터가 저장되는 공간이다. 서로 다른 데이터가 해시 연산 결과 같은 버킷에 배정될 수 있으며(collision), 충돌이 발생하면 해당 버킷 안에 linked list 형태로 데이터를 연결한다.
특정 버킷에 50개의 데이터가 linked list로 연결되었다고 가정하자. COUNT 10 으로 SSCAN 을 진행하여 그 버킷을 방문하면 해당 버킷의 모든 데이터를 읽어 리턴한다.
만약 해시 테이블의 크기는 크나 데이터가 드문드문 저장되어 있는 경우, 확인한 버킷이 모두 비어이있을 수도 있다. 이 경우 빈 리스트를 리턴하며, 검사해야 할 버킷들이 남아있으므로 커서는 0이 아닌 다음 위치값을 리턴한다.
SSCAN은 stateless 방식이다. 클라이언트의 커서 번호에만 의존한다. 순회 도중 Set의 데이터가 추가되거나 삭제되어 해시 테이블의 크기가 변한다면 중복 데이터가 리턴될 수 있다.
Redis의 해시 테이블은 데이터가 많아지면 크기를 2배로 늘리는데, 이를 rehashing이라고 한다. 테이블 크기가 커지면 기존 버킷에 있던 데이터들이 새로운 공간으로 재분배된다.
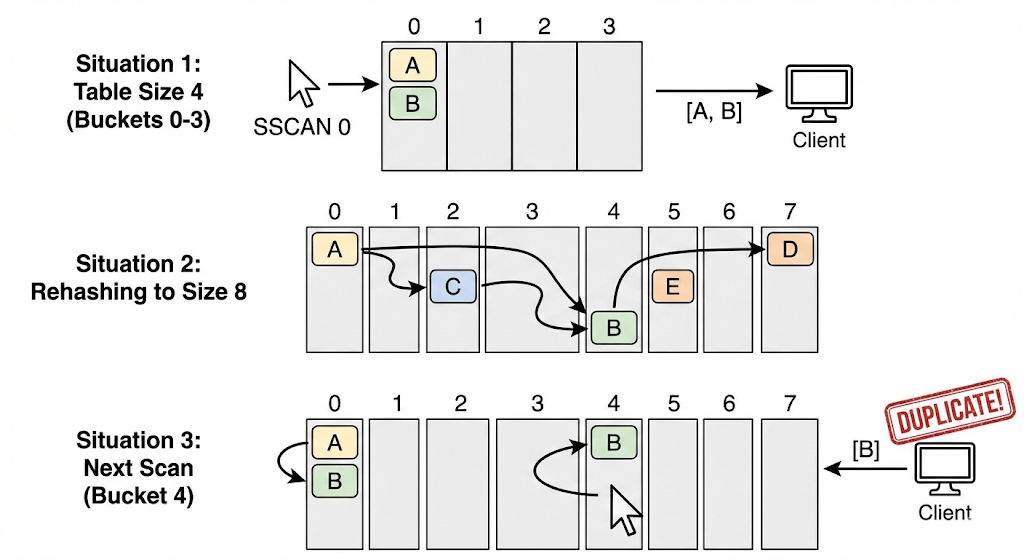
테이블 크기가 4일 때 SSCAN 0을 호출하여 버킷 0을 읽었다고 하자. 버킷 0에는 [A, B]가 있고, 클라이언트는 [A, B]를 받는다.
클라이언트가 다음 커서를 요청하기 전, 데이터가 추가되어 테이블 크기가 8로 확장되었고, 재분배가 발생한다.
이후 다음 커서가 가리키는 버킷이 4인 경우, [B]를 중복하여 받게 된다.
설명의 편의 상 0, 1, 2, … 번 버킷이라고 명명한 것이지, 방문 순서가 0, 1, 2, …번 버킷 순은 아니다.
SRANDMEMBER
SRANDMEMBER key [count]
SRANDMEMBER 명령은 Set에서 임의의 원소를 리턴하는 명령이다. 이때 데이터를 삭제하지 않는다. 조회만 수행한다.
count가 없다면 1개를 추출하며, 양수인 경우 비복원 추출로 조회한다. count가 전체 집합 크기보다 크다면 전체 집합을 리턴한다. 음수인 경우 복윈 추출로 조회한다. 즉, 데이터 간 중복이 발생할 수 있다. 요청한 개수의 절댓값이 집합의 크기보다 커도 상관없다.
intset으로 인코딩된 경우 배열 형태이므로 인덱스가 0부터 $N$까지 명확하다. 따라서 random() % size로 추출한다.
hashtable로 인코딩된 경우 랜덤하게 버킷을 고른 후, 만약 버킷 안의 데이터가 여러 개라면 그 중 하나를 랜덤으로 골라 추출한다.
SPOP
SPOP key [count]
SPOP 은 집합에서 임의의 원소를 꺼내 삭제하는 명령이다.
hashtable로 인코딩된 경우 단순히 해당 해시 엔트리를 삭제한다. 따라서 시간복잡도는 $O(1)$이다.
intset으로 인코딩된 경우 해당 인덱스의 값을 지우고 뒤에 있는 값들을 앞으로 당긴다. 이 경우 시간복잡도는 $O(N)$이나, $N$이 작으므로 큰 오버헤드는 없다.
집합 연산
SINTER
SINTER key [key ...]
SINTER 는 여러 집합의 교집합을 구하는 명령이다. 시간복잡도는 $O(NM)$으로, $N$은 가장 작은 집합의 크기, $M$은 집합의 개수이다. 집합 중 하나라도 존재하지 않거나 비어있다면 결과는 무조건 빈 집합이다.
Redis는 교집합을 구할 때 가장 크기가 작은 집합을 기준으로 삼는다. 먼저 집합들의 크기를 확인한 후(SCARD), 가장 작은 집합의 원소들에 대하여 다른 집합에 존재하는지 여부를 확인한다(SISMEMBER).
SUNION
SUNION key [key ...]
SUNION 은 모든 집합의 원소들을 하나로 합쳐 리턴한다. 중복된 데이터는 자동으로 제거된다. 시간복잡도는 $O(N)$으로, $N$은 모든 집합에 있는 원소의 수의 합이다.
SDIFF
SDIFF key [key ...]
SDIFF 는 첫 번째 집합에서 나머지 집합들의 원소들을 빼고 남은 집합을 리턴한다. 역시 시간복잡도는 $O(N)$.
STORE
SINTERSTORE destination key [key ...]
SINTER, SUNION, SDIFF 에 STORE 접미사를 붙이면 결과를 클라이언트에게 리턴하지 않고 Redis 내부의 새로운 key에 저장한다. 리턴값은 저장된 원소의 개수이다.
단순히 결과를 받아 SADD로 저장해도 되는데 STORE 관련 명령은 왜 존재할까?
집합 연산을 통해 대량의 데이터를 클라이언트로 전송하고, 이를 저장하는 과정은 네트워크 비용 측면에서 비효율적이다. STORE 관련 명령은 집합 연산을 메모리에서 수행한 후 옆 메모리 공간에 결과를 저장한다.
또한 원자적이라는 특징이 있다. 집합 연산부터 저장까지의 과정이 하나의 트랜잭션처럼 처리된다.
다만 집합 연산을 사용할 때 CROSSSLOT 에러에 유의해야 한다.
Redis 클러스터는 샤딩을 통해 데이터를 여러 노드에 나누어 저장한다. 이때 데이터를 어느 노드에 저장할지 결정하는 기준은 해시 슬롯이다.
SINTER key1 key2 를 수행하는 상황이라고 가정하자. key1은 노드 A에, key2는 노드 B에 저장되었다. 클라이언트가 노드 A에게 SINTER key1 key2 를 요청하면, 자신의 메모리에 있는 key1을 찾는 데에는 성공하나, key2는 다른 노드에 있으므로 CROSSSLOT 에러를 던진다. Redis는 하나의 명령을 처리하기 위해 다른 노드와 통신해서 데이터를 가져오는 작업은 수행하지 않는다.
{group1}:members:team_a
이를 방지하기 위해 키들이 같은 노드에 저장되도록 강제해야 하는데, 이때 Hash Tag를 사용한다. 키 이름에 중괄호가 포함되어 있으면 Redis는 전체 키를 해싱하지 않고 중괄호 안쪽의 문자열만 해싱한다.
다만 너무 광범위한 태그를 사용되는 경우 데이터가 하나의 노드에 쏠릴 수 있으므로, 반드시 같이 연산되는 최소 집합에 대해서 같은 태그를 설정해주어야 한다.