Redis의 자료형과 명령어 - Sorted Set(ZSet)
Redis의 자료형과 명령어 - Sorted Set(ZSet)
Sorted Set(ZSet)
ZSet은 개념적으로 Set과 Hash의 특성을 합쳐놓은 형태이다. 내부적으로 member(값)과 score(가중치)가 쌍을 이루고 있다. member는 Set과 마찬가지로 중복될 수 없으며, score는 정렬을 결정하는 기준값으로 중복이 가능하며 부동 소수점 숫자로 저장된다.
score 기준으로 오름차순으로 저장되며, score가 같다면 member 문자열의 사전 순서를 2차 정렬 기준으로 사용한다.
Set과 비교하여 대부분 명령의 시간복잡도가 $O(logN)$이라는 특징을 갖는다.
인코딩 방식
listpack
원소의 개수가 적고 각 원소의 크기가 작을 때(기본값 128개, 64바이트) listpack 방식으로 인코딩한다. 문자열이 linked list와 같이 포인터로 연결되지 않고 하나의 긴 문자열 배열처럼 저장된다.
포인터 오버헤드가 없어 메모리 사용량이 매우 적으나, 데이터를 중간에 삽입 또는 삭제하는 경우 메모리 복사 비용이 발생한다.
skiplist + hashtable
ZSet에 데이터가 많아지면 Redis는 내부적으로 zset이라는 구조체를 만든다. zset 안에는 dict(해시 테이블)과 zskiplist(스킵 리스트)가 존재한다.
스킵 리스트는 linked list에 여러 level의 인덱스를 두어 $O(logN)$의 탐색 속도를 가지는 자료구조이다.
1
2
3
4
typedef struct zset {
dict *dict; // 해시 테이블, member와 score 매핑
zskiplist *zsl; // score 순서대로 정렬된 리스트
} zset;
데이터를 따로 저장하는 것이 아니라 실제 데이터는 하나만 두고 서로 포인터로 공유한다. 따라서 메모리가 2배로 드는 것은 아니다.
해시 테이블의 역할을 빠른 조회($O(1)$)이며, 스킵 리스트의 역할을 정렬과 범위 검색($O(logN)$)이다.
보통 정렬된 데이터를 다룰 때 B-Tree 또는 Red-Black Tree를 많이 사용한다. 그러나 스킵 리스트를 사용한 이유가 뭘까?
범위 검색에서 생각해보자. 균형 트리에서 시작 노드를 찾는 것은 $O(logN)$으로 빠르다. 그러나 그 다음 노드를 찾으려면 트리 순회를 해야 한다. 구현이 복잡해지며 CPU 캐시 효율이 떨어지게 된다.
스킵 리스트 역시 시작 노드를 찾는 시간은 $O(logN)$이다. 이후 다음 노드를 찾기 위해 가장 아래 레벨의 포인터를 따라가면 된다. linked list 순회와 동일하다($O(1)$).
또한 Red-Black Tree의 경우 삽입 및 삭제 시 트리의 균형을 맞추기 위해 회전, 색상 변경 등 복잡한 로직이 필요하다.
스킵 리스트는 노드를 어느 level에 배치할 지를 확률에 기반하여 결정한다. 모든 노드는 level 1에는 존재한다. 이후 랜덤하게 노드들의 level을 높인다. 대수의 법칙에 의해 노드들의 level 분포는 피라미드 형태를 띄게 된다. 노드의 수가 $N$개라면 높이는 $logN$에 비례하므로 탐색 속도는 $O(logN)$이 된다.
트리가 자식에 대한 두 개의 포인터를 가지는 반면, 스킵 리스트는 확률에 기반하여 높이를 결정하므로 대부분의 노드는 높이가 낮으며, Redis 기분 평균적으로 노드 당 약 1.33개의 포인터만 사용한다.
명령어
ZADD
ZADD key [NX|XX] [GT|LT] [CH] [INCR] score member [score member ...]
ZADD는 member와 score을 ZSet에 저장하는 명령이다. 데이터를 넣는 순간 정렬된다. 데이터가 들어갈 위치를 스킵 리스트에서 찾아야 하기 때문에 시간복잡도는 $O(logN)$이다.
기본적으로 새로 추가된 데이터의 수를 리턴한다.
만약 member가 이미 존재한다면 기존 노드를 새로운 score의 위치로 이동시킨다.
NX 옵션은 member가 없을 때만 추가하고, XX 옵션은 멤버가 이미 있을 때만 score을 업데이트한다.
GT 옵션은 새로운 score가 현재 score보다 클 때, LT 옵션은 현재 score보다 작을 때만 업데이트한다.
Redis 6.2 이후부터 지원된다.
CH 옵션은 리턴값을 ‘추가된 member의 수 + score가 바뀐 member의 수’로 변경한다. 이를 통해 score 업데이트 여부를 알 수 있다.
INCR 옵션은 score을 덮어쓰지 않고 현재 score에 더한다. 후술할 ZINCRBY 명령과 동일하게 동작한다.
ZINCRBY
ZINCRBY key increment member
ZINCRBY 는 ZSet에서 member의 score를 increment만큼 증가시키는 명령이다. score가 변경되면 스킵 리스트 내에서 member의 위치가 변해야 하므로 시간복잡도는 $O(logN)$이다. 리턴값은 변경된 최종 score이다.
만약 member가 ZSet에 없다면 현재 score가 0이라고 간주하고, member와 score가 increment인 데이터가 새로 추가된다(ZADD와 동일).
score를 감소시키고 싶다면 increment에 음수를 할당하면 된다.
ZRANGE
ZRANGE key start stop [BYSCORE | BYLEX] [REV] [LIMIT offset count] [WITHSCORES]
ZRANGE는 ZSet에서 범위 기반으로 데이터를 조회하는 명령이다. Redis 6.2부터 score 기반, 사건순 기반 조회까지 처리할 수 있다.
key는 조회할 집합의 키, start와 stop은 조회할 범위의 시작과 끝이다.
BYSCORE 옵션은 인덱스가 아닌 score를 기준으로 조회한다.
BYLEX 옵션은 score가 같다는 전체 하에 사전 순서로 조회한다.
REV 옵션은 역순으로 조회한다. 과거의 ZREVRANGE 명령을 대체한다.
LIMIT 옵션으로 페이징 기능을 사용할 수 있다.
WITHSCORES 옵션을 사용하면 member와 함께 score도 같이 리턴한다.
먼저 start에 맞는 첫 번째 노드를 인덱스를 타고 찾는다($O(logN)$). 이후 시작 노드부터 stop까지 level 0의 linked list 포인터를 타고 옆으로 이동하며 데이터를 가져온다($O(M$), $M$은 가져오는 데이터의 수). 따라서 ZRANGE 명령의 시간복잡도는 $O(logN+M)$이다.
ZRANK, ZREVRANK
1
2
ZRANK key member
ZREVRANK key member
ZRANK와 ZREVRANK는 ZSet에서 member의 순위를 조회하는 명령이다. ZRANK는 오름차순 순위, ZREVRANK는 내림차순 순위이다.
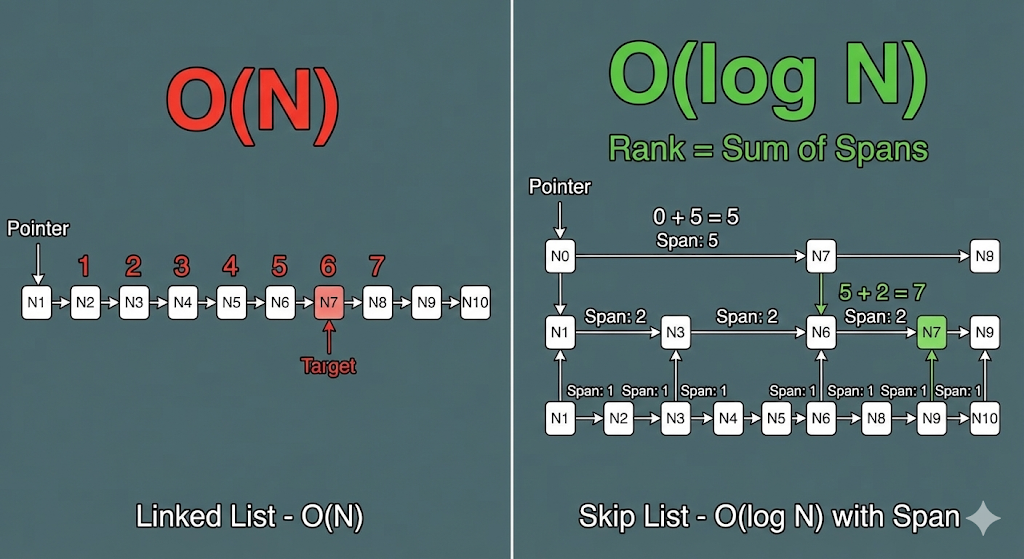
List에서 특정 데이터의 인덱스를 찾으려면 처음부터 세야 하므로 $O(N)$이 걸린다. 그러나 ZSet은 $O(logN)$으로 인덱스를 찾는다.
스킵 리스트는 몇 개의 노드를 건너뛰었는지에 대한 거리 정보를 함께 저장한다. 명령이 들어오면 해당 노드까지 $O(logN)$으로 찾고, 이후 모든 링크의 거리를 더한 값이 곧 순위가 된다.
ZSCORE, ZMSCORE
ZSCORE key member
ZMSCORE key member [member ...]
ZSCORE, ZMSCORE은 member의 score을 조회하는 명령이다. ZMSCORE은 여러 member의 score을 한 번에 조회한다.
순위를 탐색할 때는 순서를 세야 했으므로 스킵 리스트를 탐색해야 했다. 그러나 score는 값만 알면 되므로 해시 테이블을 조회하면 되므로, 시간복잡도는 $O(1)$이다.
ZREM
ZREM key member [member ...]
ZREM 은 member를 삭제하는 명령이다. 리턴값은 실제로 삭제된 member의 수이다.
ZSet은 스킵 리스트, 해시 테이블의 이중 구조로 되어 있으므로 삭제 시 두 곳에서 모두 데이터를 삭제해야 한다.
먼저 해시 테이블에서 member를 찾아 삭제한다($O(1)$). 이때 해당 member의 score을 알아낸다. 이후 알아낸 score과 member를 통해 스킵 리스트를 탐색하여 삭제한 후, 끊어진 포인터들을 앞뒤로 연결한다. 이 과정에서 $O(logN)$의 시간복잡도를 가지게 된다.
ZPOPMIN, ZPOPMAX
1
2
ZPOPMIN key [count]
ZPOPMAX key [count]
ZPOPMIN은 score가 가장 낮은 member를, ZPOPMAX는 score가 가장 높은 member를 꺼내는 명령이다. 조회 및 삭제가 동시에 일어난다.
count는 꺼낼 개수를 지정하는 인자이다.
스킵 리스트에서 노드 삭제 후 정리하는 과정($O(logN)$)이 필요하므로 시간복잡도는 $O(logN \cdot M)$이다. $N$은 집합의 크기, $M$은 꺼낼 개수이다.
스킵 리스트는 항상 정렬된 상태로 유지되므로, 최댓값과 최솟값을 찾기 위해 스킵 리스트를 탐색하지 않아도 된다. 단순히 head 또는 tail에 접근 후 제거하면 된다.
ZREMRANGEBYRANK, ZREMRANGEBYSCORE
ZREMRANGEBYRANK, ZREMRANGEBYSCORE은 ZSet을 대량으로 정리할 때 사용하는 명령이다. 하나만 삭제하는 ZREM과 달리, 범위를 지정하여 한 번에 여러 데이터를 삭제한다.
ZREMRANGEBYRANK key start stop
ZREMRANGEBYRANK는 순위를 기준으로 범위를 지정하여 삭제한다. start와 stop은 음수 인덱스도 허용한다. 시간복잡도는 $O(logN+M)$이다. 삭제 범위의 시작 노드를 찾기 위해 $O(logN)$의 시간복잡도를 가지고, $M$개의 노드를 삭제하는 과정에서 $O(M)$의 시간복잡도를 가진다.
ZREMRANGEBYSCORE key min max
ZREMRANGEBYSCORE은 점수가 min 이상 max 이하인 모든 member를 지운다. 범위는 음의 무한대부터 양의 무한대까지 전부 가능하다. 역시 시간복잡도는 $O(logN+M)$이다.
ZRANGEBYLEX
ZRANGEBYLEX key min max [LIMIT offset count]
ZRANGEBYLEX은 집합을 사전 순서대로 조회하는 명령이다. 다만 이 명령을 사용할 때는 score가 모두 동일해야 한다. ZSet은 일차적으로 score를 기준으로 정렬하고 member로 정렬하므로 score가 다르게 되면 member 정렬도 의미가 없어지기 때문이다. 따라서 보통 ZRANGEBYLEX를 사용할 때는 score을 모두 0으로 고정해서 저장한다.
1
2
3
> ZRANGEBYLEX dictionary - +
>
> ZRANGEBYLEX dictionary [ap (aq
특수 기호를 반드시 사용해야 한다. [는 닫힌 구간, (은 열린 구간을 의미한다. -은 음의 무한대, +은 양의 무한대를 의미한다.
범위 탐색과 동일한 방식으로 탐색하므로 시간복잡도는 $O(logN+M)$이다.
Redis 6.2 이후에는 ZRANGE로 통일되었다.
집합 연산
ZINTER
ZINTER numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX] [WITHSCORES]
ZINTER는 ZSet에서 교집합을 구하는 명령이다. SINTER과 유사하나, 공통된 member를 찾았을 때 score는 어떻게 계산할 것인지가 핵심이다.
numkeys는 교집합을 구할 집합의 개수이다.
WEIGHTS는 각 집합의 score에 곱할 가중치(기본값 1)이며, AGGREGATE는 겹치는 member의 score을 합치는 방식이며, SUM, MIN, MAX가 가능하다. 기본값은 SUM이다. WITHSCORES를 사용하면 결과를 리턴할 때 score 또한 같이 리턴한다.
AGGREGATE가 SUM이면 겹치는 member의 score을 더하고, MIN이면 최솟값을, MAX면 최댓값을 취한다.
SINTER와 마찬가지로 가장 작은 집합을 기준으로 루프를 도며 member가 다른 집합에 존재하는지 확인한다. 따라서 교집합을 찾는데 걸리는 시간복잡도는 $O(N \cdot K)$이다($N$: 가장 작은 집합의 크기, $K$: 집합의 개수).
결과를 다시 정렬하는데 걸리는 시간복잡도는 $O(MlogM)$이다. $M$은 교집합의 크기이다.
위와 같은 시간복잡도가 나온 이유는 퀵 정렬을 사용하기 때문이다.
따라서 전체 시간복잡도는 $O(N \cdot K + MlogM)$이다.
ZUNION
ZUNION numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX] [WITHSCORES]
ZUNION은 ZSet에서 합집합을 구하는 명령이다.
인자는 이전과 동일하다.
합집합은 모든 데이터를 다 읽어야 하므로 전체 순회가 필연적이다. 따라서 이때 걸리는 시간복잡도나느 $O(N)$이며($N$: 모든 집합의 원소 수의 합), 결과를 정렬하는데 $O(MlogM)$으로($M$: 합집합의 크기), 전체 시간복잡도는 $O(N+MlogM)$이다.
합집합 연산은 데이터가 많아질 가능성이 크므로 실무에서는 ZUNIONSTORE 명령을 통해 합집합 결과를 저장한 후 ZRANGE를 통해 페이징 조회하는 방식을 사용한다.
ZDIFF
ZDIFF numkeys key [key ...] [WITHSCORES]
ZDIFF 명령은 ZSet에서 차집합을 구하는 명령이다.
인자는 위와 동일하다.
차집합 결과의 score는 기존 집합의 score을 그대로 유지한다.
차집합을 구하기 위해 모든 집합을 조회해야 하므로 전체 조회에서의 시간복잡도는 $O(L)$이다($L$: 모든 집합의 원소 수의 합). 이후 나머지 집합에 첫 번째 집합의 member가 존재하는지 확인하고 제외하는 과정하는데 시간복잡도는 $O(N-K) \cdot logN$이다($N$: 첫 번째 집합의 크기, $K$: 차집합 연산 후 남은 최종 개수 == $N-K$: 삭제된 데이터의 수).