📌 모델링
- 데이터 관점의 업무 분석 기법
- 현실 데이터를 약속된 표기법으로 표현하는 과정
- DB를 구축하기 위한 분석 및 설계 과정
특징
- 단순화: 핵심 요소에 집중, 불필요한 요소는 제거하자
- 추상화: 간략하게 표현하자
- 명확화: 정확하게 표현하자
관점
- 데이터 관점: 어떻게 데이터가 저장, 접근, 관리되는지
- 프로세스 관점: 시스템이 어떤 작업을 수행하며 어떻게 조직되는지, 데이터가 어떻게 변환되는지
- 데이터와 프로세스 관점: 시스템 전반적인 동작 이해
유의점
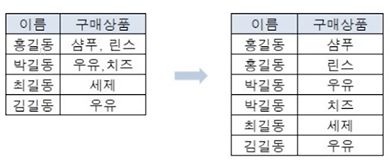
- 중복: 데이터의 중복(같은 정보를 저장)을 피하자 ↔ 유일성
- 비유연성: 사소한 변화에도 잦은 모델 변경이 되는 것을 피하자 ↔ 유연성
- 데이터 정의를 프로세스와 분리
- 비일관성: 모순된 내용이 저장되는 것을 피하자 ↔ 일관성
- 데이터 간 관계 명확히
- 중복 없음 ≠ 비일관성
모델링 3요소
- 엔티티
- 속성
- 관계
모델링 3단계
- 개념적 모델링: 핵심 엔티티를 추출하는 단계, ERD 작성
- 논리적 모델링: 식별자, 관계 등을 표현하는 단계, 정규화 수행, 재사용 가능
- 물리적 모델링: 직접 물리적으로 생성하는 단계, 저장구조, 가용성 고려
📌 스키마
구분
- 외부 스키마: 사용자가 보는 관점에서 정의됨, == 뷰
- 개념 스키마: 논리적 모델링에서 만들어진 스키마, 전체 논리적 구조 정의(엔티티, 속성, 관계 등), 통합적 표현
- 내부 스키마: 물리적 모델링에서 만들어진 스키마, 저장 구조, 컬럼, 인덱스 등 정의
스키마의 독립성
- 독립성: 물리적, 논리적 구조를 변경하더라도 응용 프로그램에 영향 X
- 논리적 독립성: 개념 스키마가 변경되어도 영향 안 줌
- 물리적 독립성: 내부 스키마가 변경되어도 영향 안 줌
📌 ERD
- 엔티티 간 관계를 시각적으로 표현한 다이어그램
- 가장 중요한 엔티티는 좌상단에 표기한다.
구성 요소
ERD 작성 6단계
- 엔티티 도출
- 엔티티 배치
- 엔티티 간 관계 설정
- 관계 이름 서술
- 관계 참여도(차수) 서술
- 관계 필수 여부 확인
📌 엔티티
- 독립적으로 식별 가능한 객체 또는 사물
- 인스터스(행), 속성의 집합
- 단수 명사를 사용한다.
- 유일한 식별자에 의해 식별되어야 함
- 필요한 정보여야 함
- 최소 2개의 인스턴스의 집합으로 구성되어야 함
- 최소 2개의 속성을 가져야 함
- 실제로 사용되어야 함
- 다른 엔티티와 최소 1개의 관계 성립해야 함
분류
- 유형과 무형
- 유형 엔티티: 실체가 있는 대상
- 개념 엔티티: 물리적인 형태 X
- 사건 엔티티: 업무 수행에 따라 생성되는 대상(주문, 미납 등)
- 발생 시점
- 기본 엔티티: 원래 존재함, 고유 식별자를 가짐
- 중심 엔티티: 기본 엔티티로부터 발생됨, 중심적인 역할
- 행위 엔티티: 2개 이상의 부모 엔티티로부터 발생됨
명명
- 현업에서 사용하는 용어 사용
- 약어 자제
- 단수 명사
- 유일한 이름
- 엔티티 특징 그대로
표현
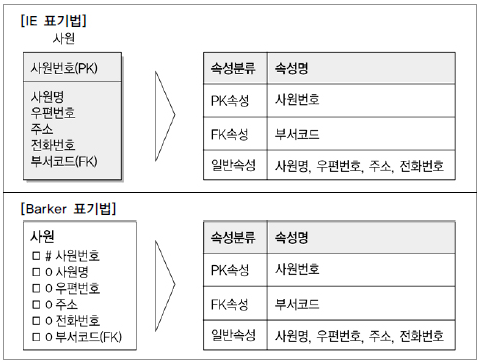
- 엔티티는 사각형으로 표현, 속성은 조금씩 다르긴 함
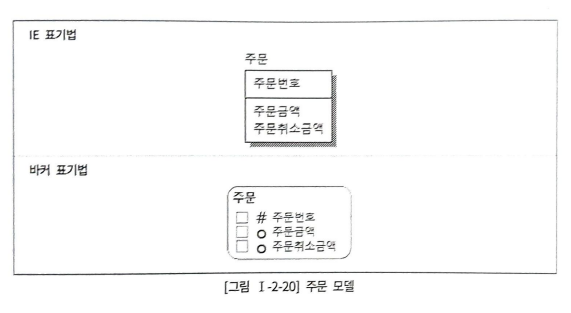
- IE 표기법: PK를 최상단에
- Barker 표기법: PK이면 앞에 # 기호 붙임
📌 속성
- 속성: 고유한 성질, 특징, 더 이상 분리되지 않는 최소 데이터 단위, 컬럼
특징
- 주 식별자에 함수적 종속성을 가져야 한다.
- 한 개의 속성은 한 개의 속성 값을 가진다.(원자성) 다중 값이라면 별도의 엔티티를 사용하여 분리한다.
- 속성도 집합이다.
분류
- 기본 속성: 업무로부터 추출됨
- 설계 속성: 업무를 규칙화하기 위한 속성(상품코드 등)
- 파생 속성: 다른 속성에 의해 파생됨(합계 등) - 원래 속성값을 계산하여 저장하는 등
- PK: 인스턴스를 고유하게 식별하는 속성
- FK: 다른 엔티티와 관계를 맺는 속성
- 일반 속성: PK, FK 이외 속성
- 단일 속성: 하나, 유일 ex) employee_id
- 복합 속성: 여러 의미, 쪼갤 수 있음 ex) address, 시, 구, 동으로 쪼갤 수 있음
- 다중 값 속성: 여러 값을 가질 수 있는 속성 ex) phone_number, 한 사람이 여러 개의 전화번호를 가질 수 있음
명명
- 업무에서 사용하는 단어
- 서술식 X
- 약어 X
- 전체 데이터 모델에서 유일한 이름을 가지도록
도메인
📌 관계
- 관계: 엔티티 간 연관성을 나타냄
- 엔티티가 명사적 표현이라면 관계는 동사적 표현임
종류
- 존재적 관계: 다른 엔티티의 존재에 영향을 미치는 관계, == 연관 관계, 식별자 관계
- 강한 연결 관계, 자식 식별자 구성에 포함, 부모 엔티티에 종속
- 행위적 관계: 엔티티 간 어떤 행위가 있음, == 의존 관계, 비식별자 관계
- 약한 연결 관계, 자식 일반 속성에 포함
- ERD는 위 관계를 구분하지 않는다.
- UML은 연관 관계는 실선, 의존 관계는 점선으로 표현
- 연관 관계는 멤버 변수로 선언, 의존 관계는 오퍼레이션에서 파라미터로 사용
구성 요소
- 관계 이름
- 차수
- 선택성
차수
- 완전 1 대 1 관계: 하나의 엔티티에 하나의 엔티티만 관계
- 선택적 1 대 1 관계: 하나의 엔티티가 하나와 관계 또는 없는 경우
- 1 대 N 관계: 하나의 행에 다른 엔티티 값이 여러 개 있는 관계
- M 대 N 관계: 조인 시 카티션 곱이 발생하므로 1 대 N 관계로 쪼개야 함
페어링
- 관계의 페어링: 인스턴스가 개별적으로 관계를 가지는 것
차수 vs. 페어링
- 차수: 엔티티 간 레코드 연결 방식
- 페어링: 두 엔티티 간 특정 연결을 설명
표기
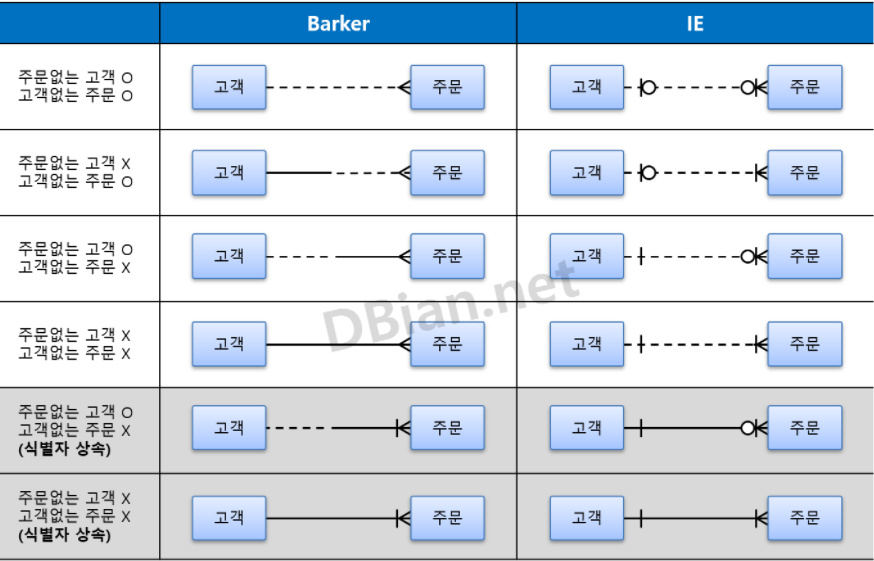
- 의존성 측면
- Barker: 실선(의존, 필수), 점선(의존 X, 선택)
- IE: 선(의존, 필수), 동그라미(의존 X, 선택)
- 식별자 상속 측면
- Barker: 세로선(식별 관계), 없음(비식별 관계)
- IE: 실선(식별 관계), 점선(비식별 관계)
📌 식별자
- 엔티티를 대표할 수 있는 속성
- 하나의 엔티티는 유일한 식별자가 존재함
- 논리 모델링: 식별자, 물리 모델링: 키
주 식별자 특징
- 유일성: 인스턴스를 유일하게 식별
- 최소성: 주 식별자 속성은 유일성을 만족하는 최소한의 속성으로 구성됨
- 불변성: 한 번 지정되면 값은 변하면 안 됨
- 존재성: 값이 존재해야 한다(널 X)
분류
- 주 식별자: 유일성, 최소성 만족, 엔티티 대표, 인스턴스를 유일하게 구분, 다른 엔티티와 참조 관계 연결 가능
- 이름을 주 식별자로 설정할 수 없다. 동명이인이 있을 수 있기 때문
- 보조 식별자: 인스턴스를 유일하게 구분할 수 있으나 대표성을 가지지 못함 → 참조 연결 X, 대표성 X
- 내부 식별자: 참조 없이 엔티티 내부에서 스스로 생성됨
- 외부 식별자: 타 엔티티의 관계를 통해 만들어지는 식별자
- 단일 식별자: 하나의 속성
- 복합 식별자: 2개 이상의 속성
- 본질 식별자(원조 식별자): 기존에 있음
- 인조 식별자: 인위적으로 만들어짐, 예: 자동 증가
- 본질 식별자가 복잡한 구성을 가질 때 만들어짐
- 단점: 중복 데이터 발생 가능, 불필요한 인덱스 생성, DML 성능 저하 → 인조 식별자가 반드시 좋은 게 아님
- 인덱스는 조회 성능을 향상시키기 위한 객체이다.
주 식별자 도출 기준
- 자주 사용되는 속성
- 명칭, 내역과 같은 이름 피함(부서명 말고 부서코드 같은 거로)
- 최대한 적은 속성의 수 사용(최소성) → 조인 성능저하를 막기 위함
식별, 비식별 관계
- 강한 개체: 독립적으로 존재할 수 있음
- 약한 개체: 독립적으로 존재 X
- 식별 관계: 엔티티의 기본 키를 다른 엔티티가 기본 키의 일부로 공유하는 관계, ERD에서 실선으로 표기
- 비식별 관계: 강한 개체의 기본 키를 다른 엔티티에서 일반 속성으로 관계를 가지는 것, ERD에서 점선으로 표기
📌 키
종류
- 기본 키: 엔티티를 대표하는 키, PK
- 후보 키: 유일성과 최소성을 만족하는 키, 후보 키 중 하나가 기본 키가 됨, 나머지는 대체 키
- 슈퍼 키: 유일성 만족, 최소성 만족 X
- 대체 키: 후보 키 중 기본 키가 아닌 키
- 외래 키: 다른 테이블의 기본 키를 참조하는 키, FK
📌 함수적 종속성
- 함수적 종속성: 속성 A에 의해 다른 속성 B가 유일하게 결정되면 B는 A에 함수적으로 종속되었다 라고 표현함. A → B
- ex) 속성이 a, b, c, d, e인 관계에서 ab→cde가 성립한다고 하면, ab로 다른 속성을 모두 결정하므로 후보 키가 된다. 추가로 e→b를 만족한다면, ae→ab이고, ab→cde이므로 ae→cde이다. 따라서 ae 또한 후보 키가 될 수 있다.
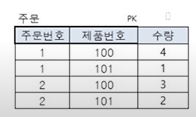
- 완전 함수적 종속: 특정 컬럼이 기본 키에 완전히 종속
- 수량 컬럼은 기본 키인 (주문번호, 제품번호) 컬럼에 의해 종속된다.
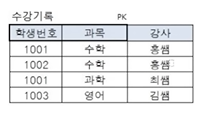
- 부분 함수적 종속: 기본키 일부에 의해 컬럼이 종속
- 강사 컬럼은 기본 키의 일부 컬럼인 과목 컬럼에 의해 종속된다.
📌 데이터 무결성
- 정확성과 일관성 유지, 결속 및 부정합이 없음을 보증하는 것
- 무결성이란? DB 값 == 현실 비즈니스 모델 값
데이터 무결성의 종류
- 개체 무결성: 기본 키는 NULL 및 중복 값 불가능
- 참조 무결성: 외래 키는 NULL이거나 참조 테이블의 기본 키와 동일해야 함
- 도메인 무결성: 속성 값이 정의된 도메인에 속한 값이어야 함
- NULL 무결성: 특정 속성은 NULL 허용 X
- 고유 무결성: 특정 속성은 중복 허용 X
- 키 무결성: 하나의 관계는 최소 하나의 키가 존재해야 함
📌 정규화
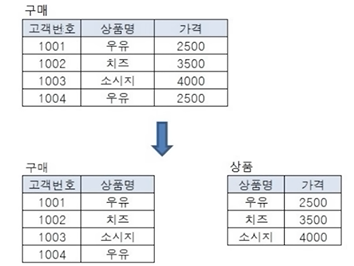
- 테이블 분해하는 개념, 최소한의 데이터를 하나의 엔티티에 넣도록 분해
- 왜? 중복 제거 → 독립성 확보, 이상현상 줄임
- 논리 모델링 수행 시점에서 고려됨
이상현상
- 삽입 이상: 불필요한 정보까지 삽입됨
- 갱신 이상: 불필요한 정보까지 갱신됨
- 삭제 이상: 불필요한 정보까지 삭제됨
정규화 단계
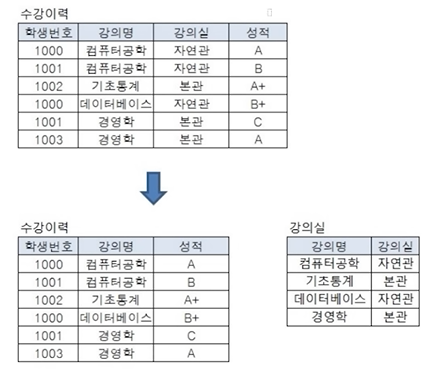
- 제 2 정규화(2NF)
- 1NF에서 완전 함수 종속이 되도록
- 완전 함수 종속: 기본 키의 모든 컬럼이 다른 컬럼을 결정함, 기본 키의 부분집합이 다른 컬럼과 일대일 대응 관계를 맺으면 안 됨 == 부분 함수 종속(기본키의 일부 컬럼에 의해 특정 속성이 결정됨)을 만족하지 않도록 해야 함
- 위 예제에서 제2정규화 수행 전 테이블에서 기본 키의 일부 속성인 ‘강의명’이 ‘강의실’을 결정함 → 완전 함수 종속 위배
- 제 3 정규화(3NF)
- 2NF에서 이행적 종속을 없애도록, A→B, B→C를 만족할 때 A→C가 만족하는 것을 방지
- BCNF
- 모든 결정자가 후보 키가 되도록
- 제 4 정규화
- 여러 컬럼이 하나의 컬럼을 종속시키는 경우 분해
- 제 5 정규화
- 조인에 의해 종속성이 발생되면 분해
반정규화, 비정규화
- 반정규화: 데이터 중복을 허용하여 조인을 줄임 → DB 성능 향상 but 모델 유연성 감소
- 언제? 수행 속도 느린 경우, 다량의 범위를 자주 처리하는 경우, 특정 범위 데이터만 자주 처리, …
- 비정규화: 정규화를 수행하지 않은 것
- 일반적으로 정규화를 권장하나, 정답은 아님
📌 관계와 조인
- 관계는 엔티티와 인스턴스 간 논리적 연관성
- 관계를 맺는다 == 부모 식별자를 자식에게 상속, 상속된 속성을 조인 키로 활용
- 조인이란 식별자를 상속하고 상속된 속성을 매핑 키로 활용하여 데이터를 결합하는 것
📌 트랜잭션
- 하나의 연속적인 업무 단위, 트랜잭션에 의한 관계는 필수적인 관계
- All or Nothing
- 트랜잭션 내부 작업이 독립적으로 발생하면 안 되며, 부분 커밋 불가능
관계와 트랜잭션
- 두 엔티티 관계가 필수적 → 하나의 트랜잭션 생성
- 두 엔티티가 독립적 수행이 가능하다면 선택적 관계로 표현
특성
- 원자성: 연산은 모두 실행되거나 전혀 실행되지 않음
- 일관성: 연산 이전에 데이터에 잘못 없다면 연산 이후에도 잘못이 있으면 안됨
- 고립성: 연산 도중 다른 트랜잭션 영향 받지 않음
- 지속성: 트랜잭션이 성공적으로 수행되면 영구 저장됨
📌 NULL
- NULL: 아직 정해지지 않은 값
- 오라클에서 ‘ ‘은 NULL임, SQL Server는 그렇지 않음
연산
- 널을 포함한 산술연산 결과는 항상 널이다.
- 집계함수는 널을 무시한다. 즉, AVG도 널을 무시한 평균값이라는 것임
- 널에 대한 모든 비교 연산은 unknown이다.
- INNER JOIN 또는 NATURAL JOIN 시 널을 포함한 행은 생략된다.
- 널 집합에 대한 COUNT 결과는 0이다. 나머지 집계함수 결과는 NULL이다. 단, 이는 공집합인 경우도 적용된다.
- 널 그룹도 GROUP BY로 출력됨
- HAVING 결과에 만족하는 그룹이 없다면 공집합 리턴됨
널 함수
- NVL, NVL2, COALESCE, ISNULL은 NULL을 특정 값으로 치환
- DECODE, CASE로 NULL 치환 가능
- SQL Server의 NULLIF는 특정 값과 같은 값을 NULL로 치환
표기법
- IE: 널 허용 여부 파악 불가
- Barker: 널 허용되면 속성 앞에 동그라미
- 참고: 필수 속성(널 허용 X) 속성은 앞에 *
📌 DB와 DBMS
- DB: 데이터의 집합
- DBMS: DB를 관리하기 위한 시스템, MySQL, Oracle 등
RDB
- 계정: 각 계정은 데이터에 대한 접근 제한 수준을 가지고 있다.
- 테이블: DB 안에 데이터가 저장되는 형식
- 스키마: 테이블에 대한 메타데이터가 정의된 데이터
- 분류, 정렬, 탐색 빠름
- 신뢰성 Good, 무결성 보장
- 이미 작성된 스키마는 수정 힘듦
- DB 부하 분석 어려움
테이블
- 행과 열로 이루어진 2차원 구조, 데이터를 저장하는 최소 단위
- 하나의 테이블은 하나의 계정이 소유해야 함
- 테이블 간 여러 관계를 가질 수 있음
- 기본적으로 테이블 이름은 중복 불가능이지만 계정이 다르다면 같은 테이블명 생성이 가능하다.
- 행 단위로 입력, 삭제가 이루어지며 셀 단위로 수정이 이루어짐
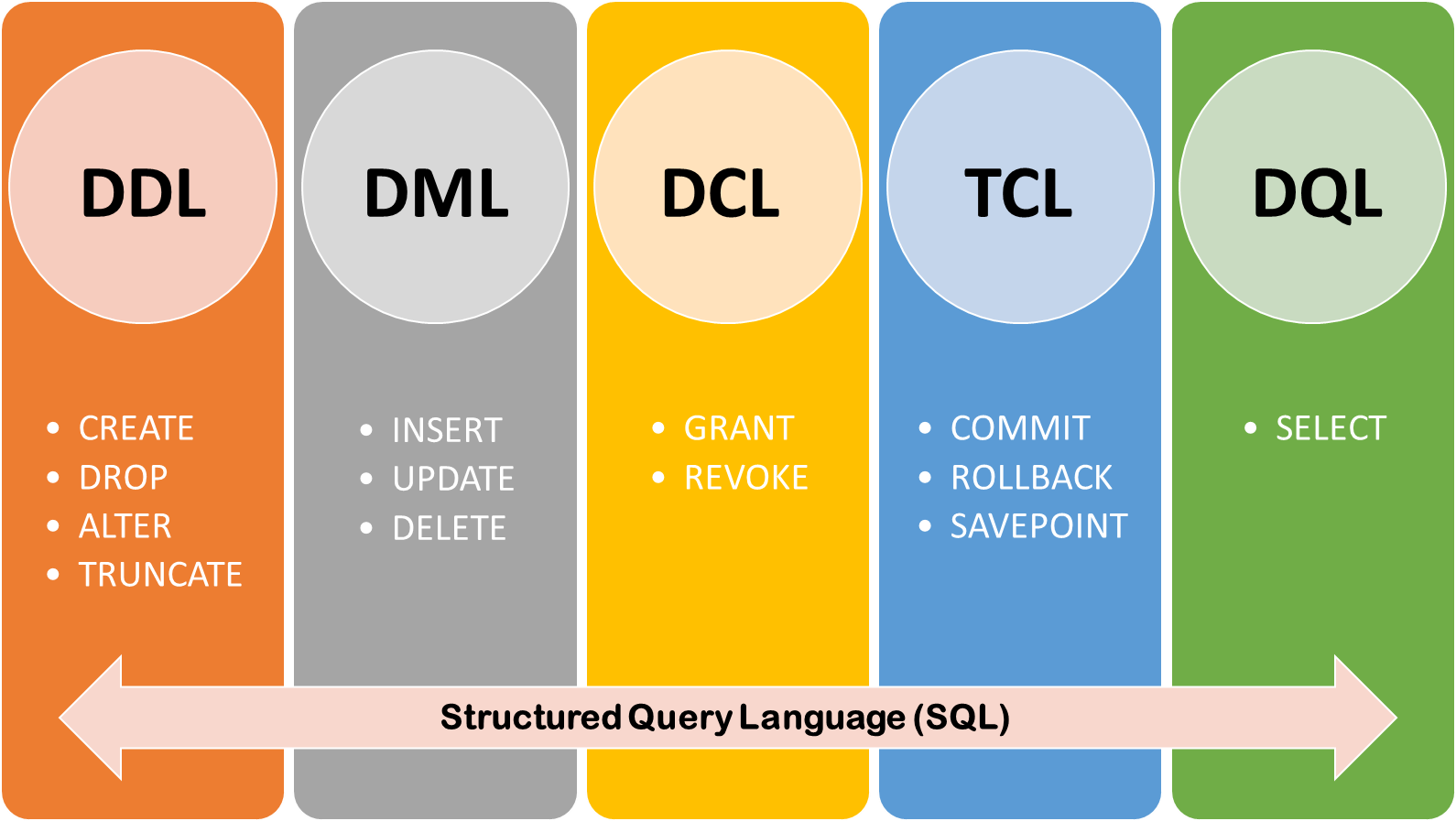
📌 SQL
- DDL: DB 구조를 정의하고 관리하는 SQL, 자동 커밋 - Definition
- DML: DB 내 데이터를 조작하는 SQL - Manipulation
- DCL: DB에 대한 접근 권한을 제어하는 SQL - Data Control
- TCL: DB 트랜잭션을 관리하는 SQL - Transaction Control
- DQL: DB 데이터를 조회하는 SQL - Query
📌 SELECT
- 작성 순서: SELECT→ FROM →WHERE →GROUP BY → HAVING → ORDER BY
- 단, GROUP BY와 HAVING은 순서 바꿀 수 있으나 권장 X
- 파싱(실행) 순서: FROM→WHERE→GROUP BY→HAVING→SELECT→ORDER BY
- 표현식: 표현 가능한 식(함수식, 연산식 등)
- SELECT COL FROM A, B에서, A, B 테이블 모두 컬럼 COL을 가지는 경우, 어느 테이블의 COL인지 명시해야 한다. 예를 들어, SELECT B.COL FROM A, B
alias
- alias: 별칭, SELECT 절에서만 정의 가능, AS 절(생략 가능), 대소문자 구분 X
- SELECT절에서 설정된 별칭은 ORDER BY에서만 사용 가능하다. SELECT보다 늦게 파싱되기 때문
- 쌍따옴표로 묶어야 하는 경우: 별칭에 공백이 있음, 특수문자(언더바 제외)가 있음, 별칭 그대로(대소문자까지) 전달하고 싶음
합성 연산자
- 오라클: ||
- SQL Server: +
- 두 문자열 접합: CONCAT
📌 함수
- 인풋과 아웃풋의 관계를 정의한 객체
- FROM 절 이외 모든 절에서 사용 가능함
분류
- 입력 수
- 단일행 함수: 인풋과 아웃풋의 관계가 일대일
- 복수행 함수: 여러 인풋을 받아 하나의 아웃풋으로(데이터 요약), 집계함수
- 입출력 타입
- 문자형 함수: 문자열 관련 연산 수행, 단일행 함수
| 함수 | 설명 | 예시 | 결과 |
|---|
| LOWER(대상) | 문자열을 소문자로 | LOWER(‘ABC’) | abc |
| UPPER(대상) | 문자열을 대문자로 | UPPER(‘abc’) | ABC |
| SUBSTR(대상,m,n) | 문자열 중 m위치에서 n개의 문자열 추출 | SUBSTR(‘ABCDE’,2,3) | BCD |
| INSTR(대상, 찾을문자열,m,n) | 대상에서 찾을문자열 위치 반환 | INSTR(‘A#B#C#’,’#’) | 2 |
| LTRIM(대상, 삭제문자열) | 문자열 중 특정 문자열을 왼쪽에서 삭제 | LTRIM(‘AABABA’,’A’) | BABA |
| RTRIM(대상, 삭제문자열) | 문자열 중 특정 문자열을 오른쪽에서 삭제 | RTRIM(‘AABABAA’,’A’) | AABAB |
| TRIM(대상) | 문자열 중 특정 문자열을 양쪽에서 삭제 | TRIM(‘ ABCDE ‘) | ABCDE |
| LPAD(대상,n,문자열) | 대상 왼쪽에 문자열을 추가하여 총 n의 길이 리턴 | LPAD(‘ABC’,5,’*’) | **ABC |
| RPAD(대상,n,문자열) | 대상 오른쪽에 문자열을 추가하여 총 n의 길이 리턴 | RPAD(‘ABC’,5,’*’) | ABC** |
| CONCAT(대상1, 대상2) | 문자열 결합 | CONCAT(‘A’,’B’) | AB |
| LENGTH(대상) | 문자열 길이 | LENGTH(‘ABCDE’) | 5 |
| REPLACE(대상,찾을문자열,바꿀문자열) | 문자열 치환 및 삭제 | REPLACE(‘ABBA’,’AB’,’ab’) | abBA |
| TRANSLATE(대상, 찾을문자열, 바꿀문자열) | 글자를 1대1로 치환 | TRANSLATE(‘ABBA’,’AB’,’ab’) | abba |
| 함수명 | 함수기능 | 사용예시 | 출력 |
|---|
| ABS(숫자) | 절대값 반환 | ABS(-1.5) | 1.5 |
| ROUND(숫자, 자리수) | 소수점 특정 자리에서 반올림 | ROUND(123.456,2) | 123.46 |
| TRUNC(숫자, 자리수) | 소수점 특정 자리에서 버림 | TRUNC(123.456,2) | 123.45 |
| SIGN(숫자) | 숫자가 양수면 1 음수면 -1 0이면 0 반환 | SIGN(100) | 1 |
| FLOOR(숫자) | 작거나 같은 최대 정수 리턴 | FLOOR(3.5) | 3 |
| CEIL(숫자) | 크거나 같은 최소 정수 리턴 | CEIL(3.5) | 4 |
| MOD(숫자1, 숫자2) | 숫자1을 숫자2로 나누어 나머지 반환 | MOD(7,2) | 1 |
| POWER(m,n) | m의 n 거듭제곱 | POWER(2,4) | 16 |
| SQRT(숫자) | 루트값 리턴 | SQRT(16) | 4 |
| 함수명 | 함수기능 | 사용예시 | 출력 |
|---|
| SYSDATE | 현재 날짜와 시간 리턴 | SYSDATE | 2024/02/14 18:44:34 |
| CURRENT_DATE | 현재 날짜 리턴 | CURRENT_DATE | 2024/02/14 |
| SYSTIMESTAMP | 현재 일시분초 리턴 | SYSTIMESTAMP | 2024/02/14 18:44:34.29 +09:00 |
| ADD_MONTHS | 날짜에서 n개월 후 날짜 리턴 | ADD_MONTHS(SYSDATE, n) | 2024/05/14 18:44:34 |
| MONTHS_BETWEEN | 날짜1과 날짜2의 개월 수 리턴 | MONTHS_BETWEEN(SYSDATE, HIREDATE) | 3.7234 |
| LAST_DAY | 주어진 월의 마지막 날짜 리턴 | LAST_DAY(SYSDATE) | 2024/02/29 |
| NEXT_DAY | 지정된 요일의 첫 번째 날짜 리턴 | NEXT_DAY(SYSDATE, 1) | 2024/02/18 18:51:35 |
| ROUND | 날짜 반올림 | ROUND(SYSDATE, ‘MONTH’) | 2024-02-01 0:00 |
| TRUNC | 날짜 버림 | TRUNC(SYSDATE, ‘MONTH’) | 2024-02-01 0:00 |
| 함수명 | 설명 | 사용예시 | 결과 |
|---|
| TO_NUMBER(문자열) | 숫자 데이터로 변환 | TO_NUMBER(‘3,000’) | 3000 |
| TO_CHAR(대상, 포맷) | 날짜적 포맷 변경 | TO_CHAR(SYSDATE, ‘MM/DD/YYYY’) | 02/14/2024 |
| TO_CHAR(대상, 포맷) | 숫자적 포맷 변경 | TO_CHAR(3000, ‘9,999’) | 3,000 |
| TO_DATE(문자, 포맷) | 문자를 날짜로 변환 | TO_DATE(‘2024/01/01’, ‘YYYY/MM/DD’) | 2024/01/01 00:00:00 |
| FORMAT(날짜, 포맷) | 날짜 포맷 문자열 변경 | FORMAT(GETDATE(), ‘YYYY’) | 2024 |
| CAST(대상 AS 데이터타입) | 데이터 데이터 타입 변환 | CAST(1 AS VARCHAR) | 1 |
| 함수명 | 함수기능 | 사용예시 | 출력 |
|---|
| COUNT(대상) | 행의 수 리턴 | SELECT COUNT(SAL) FROM EMP; | 각 연산 결과 |
| SUM(대상) | 총 합 리턴 | SELECT SUM(SAL) FROM EMP; | 각 연산 결과 |
| AVG(대상) | 평균 리턴 | SELECT AVG(SAL) FROM EMP; | 각 연산 결과 |
| MIN(대상) | 최소값 리턴 | SELECT MIN(SAL) FROM EMP; | 각 연산 결과 |
| MAX(대상) | 최대값 리턴 | SELECT MAX(SAL) FROM EMP; | 각 연산 결과 |
| VARIANCE(대상) | 분산 리턴 | SELECT VARIANCE(SAL) FROM EMP; | 각 연산 결과 |
| STDDEV(대상) | 표준편차 리턴 | SELECT STDDEV(SAL) FROM EMP; | 각 연산 결과 |
| 함수명 | 설명 | 사용예시 | 출력 |
|---|
| DECODE | 대상이 값1이면 리턴1, 값2와 같으면 리턴2, 그외에는 그외리턴 | DECODE(DEPTNO,10,A,B) | A 또는 B |
| NVL | 대상이 널이면 지정값으로 치환하여 리턴 | NVL(COMM,0) | COMM값 또는 0값 |
| NVL2 | 널이 아니면 지정값2,치환하여 리턴 | NVL2(COMM,COMM*1.1,0) | COMM*1.1값 또는 0값 |
| COALESCE | 대상들 중 널이 아닌 첫 번째 값 | COALESCE(NULL,100) | 100 |
| ISNULL | 대상이 널이면 지정값이 리턴 | ISNULL(NULL,100) | 100 |
| NULLIF | 두 값이 같으면 널, 다르면 대상1 | NULLIF(10,20) | 10 |
| CASE문 | 조건별 처리 및 연산 수행 | 없음 참고 | 없음 참고 |
- “CASE WHEN <컬럼> = 값” == “CASE <COL> WHEN 값”
📌 FROM
- 테이블 여러 개 전달 시 콤마로 구분해야 함. 콤마 미기입 시 카티션 곱 발생함
- 즉, FROM A, B == FROM A CROSS JOIN B
- 테이블 별칭 선언 가능(단, 오라클은 AS 사용 불가)
- 테이블 별칭을 사용한다면 반드시 그 별칭 사용할 것
- 23c 버전 이전 오라클은 FROM 생략 불가(필요 없다면 DUAL 테이블 선언 필요), SQL Server는 생략 가능
1
| SELECT SYSDATE AS current_date FROM DUAL;
|
뷰
- 데이터를 조회할 수 있는 객체지만 테이블처럼 실 데이터가 아님(조회용 테이블)
- 장점
- 독립성: 테이블 구조 변경에 독립적임
- 편리성: 복잡한 쿼리를 단순하게 작성 가능
- 보안성: 숨기고 싶은 정보를 제외하고 생성할 수 있다.
📌 WHERE
- 원하는 데이터 보고 싶을 때
- 여러 조건 사용 시 AND와 OR 사용
- NULL에 대한 조건은 = 말고 IS NULL 또는 IS NOT NULL 사용할 것
- 비교 대상은 데이터 타입 일치시킬 것
| 비교 연산자 | 설명 |
|---|
| = | 같은 조건을 검색 |
| !=, <> | 같지 않은 조건을 검색 |
| > | 큰 조건을 검색 |
| >= | 크거나 같은 조건을 검색 |
| < | 작은 조건을 검색 |
| <= | 작거나 같은 조건을 검색 |
| BETWEEN A AND B | A 와 B사이에 있는 범위 값을 모두 검색 |
| IN(a, b, c) | A 이거나 B 이거나 C 인 조건을 검색 |
| LIKE | 특정 패턴을 가지고 있는 조건을 검색 |
| IS NULL / IS NOT NULL | NULL 값을 검색 / NULL이 아닌 값을 검색 |
| A AND B | A 조건과 B 조건을 모두 만족하는 값만 검색 |
| A OR B | A 조건이나 B조건 중 한가지라도 만족하는 값을 검색 |
| NOT A | A가 아닌 모든 조건을 검색 |
- 오라클은 문자 상수는 대소문자 구분, MSSQL은 구분 X
- 문자, 날짜는 홑따옴표 사용
집계 함수 사용 불가
LIKE
- 문자열 패턴 전달 시 사용
- %: 자리수 제한 없는 모든 문자
- _: 한 자리수의 모든 문자
1
2
3
| SELECT *
FROM employees
WHERE first_name LIKE 'A%' OR first_name LIKE 'B%';
|
📌 GROUP BY
- 그룹 기준으로 데이터 “요약”
- 여러 개의 컬럼 지정 가능
- 그룹에 대한 조건은 WHERE에서 사용 불가
- SELECT 절에 요약 정보가 아닌 정보를 기술 불가
1
2
3
4
| SELECT product_name, SUM(quantity)
FROM sales
GROUP BY quantity;
-- product_name이 그룹화되지 않은 열이기 때문에 오류 발생
|
📌 HAVING
- 집계 결과를 조건으로 사용할 때 - WHERE 절에서 사용할 수 없으므로
- SELECT 절의 alias 사용 불가능
- GROUP BY가 없어도 사용 가능
📌 ORDER BY
- 출력 행의 순서 변경 시
- 명시된 컬럼 순서대로 정렬
- ASC: 오름차순(기본 값, 생략 가능), DESC: 내림차순
- SELECT 절의 별칭 사용 가능
1
2
3
| SELECT id, first_name, last_name
FROM employees
ORDER BY 3 DESC; -- 3번째 열인 last_name을 기준으로 내림차순 정렬
|
NULL 정렬
- 오라클: NULL을 마지막에, SQL Server: NULL을 처음에
- 오라클은 ORDER BY 절에 NULL LAST, NULL FIRST를 명시하여 NULL 위치를 지정할 수 있음
📌 JOIN
- 여러 테이블 사용하여 출력 및 참고할 때
- FROM 절에 조인 테이블 나열
- 오라클 표준: 테이블 나열 순서 중요, ANSI 표준: OUTER JOIN인 경우만 순서 중요
- 오라클은 WHERE 절에 조인 조건 작성, ANSI는 ON 절에 조인 조건 작성
- N개의 테이블 조인 시 최소 N-1개의 조인 필요
- DBMS 옵티마이저는 FROM 절의 테이블을 임의로 2개 정도로 묶어 조인을 수행한다.
순수 관계 연산자
- SELECT == WHERE 연산자
- PROJECT == SELECT 연산자
- JOIN == 다양한 JOIN 연산자
- DIVIDE는 현재 사용 X
종류
- EQUI JOIN: 조인 조건이 동등 조건인 경우
- NON EQUI JOIN: 조인 조건이 동등 조건이 아닌 경우
- INNER JOIN: 조인 조건이 성립하는 데이터만 출력
- OUTER JOIN: 조인 조건에 성립하지 않는 데이터도 출력
- NATURAL JOIN: 조인 조건 생략 시 같은 이름을 기준으로 조인
- CROSS JOIN: 조인 조건 생략 시 가능한 모든 행 출력(카티션 곱)
- SELF JOIN: 하나의 테이블에 두 번 이상 조인
- EQUI JOIN
- 같은 값을 가지는 행을 조인
- FROM 절에 조인하고자 하는 테이블 명시, 해당 테이블들은 alias 사용 가능
- 참고: NULL = NULL은 성립 자체가 안 됨
- NON EQUI JOIN
- 조건이 = 가 아닌 경우
- 설계 상 불가능한 경우도 있음
- SELF JOIN
- 스스로 조인, 같은 행끼리 관계를 갖는 경우
- 반드시 alias를 사용해야 함
- INNER JOIN
- 조인 조건이 일치하는 행만 추출, 오라클 조인 기본
- 따라서 오라클은 FROM에 테이블을 나열하고 WHERE에 조인 조건을 기술한다.
- ANSI 표준은 INNER 생략 가능
- USING이나 ON 필수 사용
- ON: 괄호 선택, 조인 조건 명시하는 곳
1
2
3
| SELECT e.first_name, d.department_name
FROM employees e
INNER JOIN departments d ON e.department_id = d.department_id;
|
- USING: 조인 컬럼 명이 같을 때 사용, 별칭 등 사용 불가, 괄호 필수
1
2
3
| SELECT e.first_name, d.department_name
FROM employees e
INNER JOIN departments d USING (department_id);
|
- NATURAL JOIN
- 동일한 이름, 데이터 타입을 가지는 모든 컬럼을 기준으로 EQUI JOIN 수행
- USING, ON, WHERE 사용 불가
- 조인에 사용된 컬럼들은 데이터 타입이 동일해야 함
- CROSS JOIN
- CROSS JOIN == Cartesian product
- 가능한 모든 데이터의 조합을 출력함
- OUTER JOIN
- 조인 조건에 동일한 값이 아닌 컬럼도 리턴할 때 사용
- OUTER 키워드 생략 가능
- 오라클은 WHERE 절에 조인 조건을 작성하므로, 기준 테이블 반대 테이블 컬럼 뒤에 (+)를 붙인다.
1
2
3
4
5
6
7
8
9
| SELECT s.StudentID, s.StudentName, g.Subject, g.Grade
FROM Students s, Grades g
WHERE s.StudentID = g.StudentID(+) ;
-- 오라클
SELECT s.StudentID, s.StudentName, g.Subject, g.Grade
FROM Students s
LEFT OUTER JOIN Grades g ON s.StudentID = g.StudentID;
-- ANSI 표준
|
- LEFT OUTER JOIN: 결과 컬럼은 왼쪽 테이블 기준, 값이 없다면 NULL
- RIGHT OUTER JOIN: 결과 컬럼은 오른쪽 테이블 기준, 값이 없다면 NULL
- FULL OUTER JOIN: 결과 컬럼은 왼, 오 테이블 컬럼의 합집합, 오라클은 지원 안함(유도는 가능)
- how? UNION 사용
📌 서브쿼리
- 쿼리 안의 쿼리
- ORDER BY, GROUP BY에는 사용 불가능
분류
- 서브쿼리 형태에 따른 분류
- 단일 행 서브쿼리
- 다중 행 서브쿼리
- 다중 컬럼 서브쿼리
- 위치에 따른 분류
- 스칼라 서브쿼리: SELECT에 사용
- 인라인뷰: FROM에 사용
- 일반 서브쿼리: WHERE에 사용
- 비연관 서브쿼리: 서브쿼리 내 메인쿼리 컬럼이 존재 X
- 연관 서브쿼리: “ 컬럼이 존재
단일 행 서브쿼리
단일행 서브쿼리: 서브쿼리 결과가 하나의 행, 서브쿼리 결과가 단 하나의 상수로 계산, 단순비교연산자 사용 가능
다중 행 서브쿼리
다중행 서브쿼리: 서브쿼리 결과가 둘 이상의 행, 단순비교연산자 사용 불가, IN, ANY, ALL 사용 가능
다중 컬럼 서브쿼리
다중컬럼 서브쿼리: 서브쿼리 결과가 두 개 이상의 컬럼으로 구성됨, 메인쿼리의 여러 컬럼을 괄호로 묶어서 비교
연관 서브쿼리
연관 서브쿼리: 서브쿼리가 메인 쿼리의 컬럼 정보를 가짐
비연관 서브쿼리
메인 쿼리에 값을 제공하기 위한 목적
인라인 뷰
인라인뷰: FROM절에서 사용하는 서브 쿼리, 대소비교가 가능해짐, 메인 쿼리 테이블과 조인 가능
스칼라 서브쿼리
스칼라 서브쿼리: SELECT절에서 사용하는 서브쿼리
📌 집합 연산자
- UNION: 합집합, 중복 제거
- UNION ALL: 합집합, 중복 제거 X
- INTERSECT: 교집합, 중복 제거
- EXCEPT: 차집합, 중복 제거
- (쿼리 …) ORDER BY … UNION (쿼리 …) ORDER BY ⇒ 불가능
📌 그룹 함수
- 그룹 함수: 그룹별 소계, 전체 총계를 구할 때 사용
- ROLLUP(a, b): (a, b) 소계, (a) 소계, 전체 총계
- CUBE(a, b): (a, b) 소계, (a) 소계, (b) 소계, 전체 총계
- GROUPING SETS: 그룹핑 대상을 명시적으로 지정
- ROLLUP(a, b) == GROUPING_SETS((a, b), (a), ())
- CUBE(a, b) == GROUPING_SETS((a, b), (a), (b), ())
- GROUPING: 소계 행을 구분하는 데 사용, 소계 행이면 1, 아니면 0 리턴
📌 윈도우 함수
- 행을 특정 기준으로 그룹화하여 집계
- SELECT <윈도우, 집계 함수> OVER (PARTITION BY , **, … ORDER BY <윈도윙절>)**
- 윈도우 함수를 A, B, …를 기준으로 그룹화한 후 윈도우 내에서 C를 기준으로 행의 순서를 정의한다.
- 윈도우 함수를 수행한다고 해서 결과 건수가 바뀌는 것은 아니다. 단순히 쿼리 결과에 윈도우 함수 결과를 적용하기 때문
윈도우 함수 종류
- ROW_NUMBER: 각 행이 1부터 순차적인 고유값을 가짐
- RANK: 동일 순위는 같은 순위, 현재 행의 순위는 앞의 누적 행의 수 + 1
- DENSE_RANK: 동일 순위는 같은 순위, 현재 행의 순위는 앞 행의 순위 + 1
- FIRST_VALUE: 파티션 내 첫 번째 값 리턴
- LAST_VALUE: 파티션 내 마지막 값 리턴
- LAG: 현재 행의 이전 행 리턴
- LEAD: 현재 행의 다음 행 리턴
- PERCENT_RANK: 지정된 값이 파티션 내에서 차지하는 비율 리턴, 0~1
- CUME_DIST: 지정된 값이 파티션 내에서 차지하는 누적 비율 리턴, 0~1
- NTILE: 결과 집합을 N개의 그룹으로 나누고 각 행이 속한 그룹 번호 리턴
- RATIO_TO_REPORT: 특정 값이 파티션 내의 총합에 대한 비율 리턴
윈도윙 절 종류
- BETWEEN A AND B: 현재 행을 기준으로 A와 B 범위의 행 포함
- UNBOUNDED PRECEDING: 현제 파티션의 시작을 첫 번째 행으로 설정
- UNBOUNDED FOLLOWING: 현재 파티션의 끝을 마지막 행으로 설정
- N PREDECING/FOLLOWING: 현재 행을 기준으로 이전/이후 N개 행 포함
- CURRENT ROW: 현재 행을 기준으로 프레임 설정
- ROWS CURRENT ROW == ROWS BETWEEN CURRENT ROW AND CURRENT ROW
📌 Top N 쿼리
- ROWNUM: 각 행이 순차적인 번호 가짐, WHERE절에서 ROWNUM 조건식이 FALSE가 되기 전까지 리턴, 번호 부여 후 ORDER BY 수행되므로 모든 절 수행 후 ROWNUM을 순차적으로 부여하기 위해서 서브쿼리를 사용해야 함
- LIMIT: 정렬된 결과에서 상위 n개 행 선택
- FETCH: 결과 집합에서 상위 N개 행 선택
- WITH TIES: 값이 동일한 경우 함께 출력
📌 계층형 질의
- 트리 구조를 가진 데이터를 처리하는 방법
- CONNECTED_BY: 부모, 자식 관계를 정의
- CONNECTED_BY PRIOR <부모> == <자식>: 역방향 전개
- CONNECTED_BY PRIOR <자식> == <부모>: 순방향 전개
- 부모와 자식은 의미적으로 파악한다
- WHERE과 같은 필터링이 아님에 유의
- START WITH: 계층 구조의 시작 위치(루트 노드) 지정
- CONNECT_BY_ROOT: 현재 행의 최상위 부모 리턴
- ISLEAF: 현재 행이 리프 노드인지 확인
- SYS_CONNECT_BY_PATH: 계층 구조의 전개 경로 리턴
- ORDER SIBILINGS BY: 동일 level에서 정렬 기준, 형제 노드 사이 정렬 지정
- SQL Server에서 계층형 질의문은 CTE(Common Table Expression, 쿼리 결과 임시 저장)을 재귀 호출하여 계층 구조를 전개
- 앵커 멤버(기본 결과 집합을 생성하는 첫 번째 쿼리)를 실행하여 기본 결과 집합을 만들고 이후 재귀 멤버를 지속적으로 실행
- 오라클에서 계층형 쿼리의 WHERE 절은 모든 전개가 완료된 후의 필터 조건이다.
- PRIOR 키워드는 SELECT, WHERE 절에서도 사용할 수 있다.
- 노드 탐색은 DFS 느낌
📌 정규식
- 정규식 표현: 문자열 공통된 규칙을 일반화하여 나타내는 방법
- REGEXP_XXX와 같은 정규 표현식을 사용 가능한 문자 함수가 존재함
| 기호 | 의미 |
|---|
| \d | 숫자 |
| \D | 숫자가 아닌 문자 |
| \w | 공백이나 특수 문자를 제외한 문자 |
| \W | 공백이나 특수 문자 |
| \s | 공백 |
| \S | 공백이 아닌 문자 |
| [[:digit:]] | 숫자 |
| [[:alpha:]] | 영문자 |
| [[:alnum:]] | 숫자 + 영문자 |
| [[:punct:]] | 특수 기호 |
| 기호 | 의미 |
|---|
| ? | 0회 또는 1회 |
| * | 0회 이상 |
| + | 1회 이상 |
| {n} | n회 |
| {n,} | n회 이상 |
| {n,m} | n회 이상 m회 이하 |
| 구문 | 의미 |
|---|
| [ab] | 현재 문자 중 하나와 일치 |
| [a-z] | 영문 소문자 한글자 |
| [A-Z] | 영문 대문자 한글자 |
| [가-힣] | 한글 한글자 |
| [*ab] | ‘a’와 ‘b’ 문자만 |
| 기호 | 설명 | | — | — | | ^ | 행의 처음 | | $ | 행의 끝 | | a | b | | ( ) | 그룹화(순서, 묶기) | | \ | escape character(일반기호) |
- REGEXP_SUBSTR: 정규식 표현식을 사용한 문자열 추출
- REGEXP_REPLACE: 정규식 표현으로 문자열 치환
- 얘는 모든 문자열 다 치환함, 단, 위치 지정 가능
- REGEXP_INSTR: 특정 패턴의 시작 위치 리턴
- REGEXP_LIKE: 특정 패턴을 갖는 경우 리턴, WHERE절에만 가능
- REGEXP_COUNT: 특정 패턴의 횟수 리턴
📌 PIVOT, UNPIVOT
- PIVOT: 행 → 열 변환, SQL 테이블 → 엑셀 시트
- UNPIVOT: 열 → 행 변환, 엑셀 시트 → SQL 테이블
- PIVOT (<집계> FOR <컬럼> IN (값에 대하여 컬럼 지정), 컬럼을 기준로 그룹화
- UNPIVOT(<그룹화컬럼> FOR <컬럼> IN (컬럼에 대하여 값 지정)
📌 DDL
- 오라클은 수행 후 AUTO COMMIT, SQL Server는 그렇지 않음
CREATE
1
2
3
4
5
| CREATE TABLE 테이블명 (
열1 데이터타입 [제약조건],
열2 데이터타입 [제약조건],
...
);
|
1
2
3
4
5
6
7
| CREATE TABLE employees (
employee_id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
age INT,
department VARCHAR(50),
salary DECIMAL(10, 2)
);
|
ALTER
- 괄호를 사용하지 않으며 여러 컬럼을 하나의 쿼리로 작업할 수 없다.
1
2
3
4
5
6
7
| ALTER TABLE 테이블명
[ADD 열명 데이터타입 [제약조건]]
| [DROP 열명]
| [MODIFY 열명 데이터타입 [제약조건]];
ALTER TABLE table_name
ADD CONSTRAINT constraint_name constraint_type (column_name);
|
1
2
| ALTER TABLE employees
ADD hire_date DATE;
|
1
2
| ALTER TABLE employees
DROP age;
|
1
2
| ALTER TABLE employees
MODIFY salary DECIMAL(12, 2);
|
1
2
| ALTER TABLE Students
ADD CONSTRAINT pk_student PRIMARY KEY (StudentID);
|
DROP
TRUNCATE
1
| TRUNCATE TABLE employees;
|
삭제 관련 명령 비교
- DROP: 저장 공간 모두 해제, 테이블 정의 자체를 완전 삭제
- TRUNCATE: 최초 생성 시 할당된 공간 빼고 해제, 초기 상태로 만듦
- DELETE: 저장 공간은 해제되지 않음, 데이터만 삭제
📌 DML
INSERT
- 삽입 컬럼을 생략하는 경우 VALUES에 모든 컬럼 값이 들어와야 함
1
2
3
4
| INSERT INTO 테이블명 (열1, 열2, ...)
VALUES (값1, 값2, ...),
(값3, 값4, ...),
...;
|
1
2
3
4
| INSERT INTO employees (employee_id, name, age, department, salary)
VALUES (2, '김철수', 28, '인사부', 45000.00),
(3, '이영희', 35, '개발부', 60000.00),
(4, '박지민', 40, '회계부', 55000.00);
|
DELETE
1
2
| DELETE FROM 테이블명
WHERE 조건;
|
1
2
3
| DELETE FROM employees
WHERE employee_id = 1;
-- 단일 행 삭제
|
1
2
3
| DELETE FROM employees
WHERE age <= 30;
-- 여러 행 삭제
|
1
2
| DELETE FROM employees;
-- 모든 행 삭제
|
UPDATE
1
2
3
| UPDATE 테이블명
SET 열1 = 새값1, 열2 = 새값2, ...
WHERE 조건;
|
1
2
3
| UPDATE employees
SET name = '김영수', department = '개발부'
WHERE employee_id = 2;
|
1
2
3
| UPDATE employees
SET salary = 50000;
-- 모든 행 수정
|
MERGE
1
2
3
4
5
6
7
8
| MERGE INTO 대상테이블 AS T
USING 원본테이블 AS S
ON 조건
WHEN MATCHED THEN
UPDATE SET T.열1 = S.열1, T.열2 = S.열2, ...
WHEN NOT MATCHED THEN
INSERT (열1, 열2, ...)
VALUES (S.열1, S.열2, ...);
|
1
2
3
4
5
6
7
8
| MERGE INTO employees AS T
USING new_employees AS S
ON T.employee_id = S.employee_id
WHEN MATCHED THEN
UPDATE SET T.name = S.name, T.department = S.department, T.salary = S.salary
WHEN NOT MATCHED THEN
INSERT (employee_id, name, department, salary)
VALUES (S.employee_id, S.name, S.department, S.salary);
|
DELETE, MODIFY 옵션
- CASCADE: 부모 테이블의 행이 삭제 및 수정 시 해당 행을 참조하는 자식 또한 삭제 및 수정됨
- SET NULL: 삭제 및 수정 시 자식 테이블의 해당 외래 키 값을 널로 설정
- SET DEFAULT: 삭제 시 정의된 기본값으로 설정
- RESTRICT: 부모 테이블의 행을 삭제 및 수정할 수 없으며 자식이 외래 키를 참조하는 경우 삭제가 제한됨
- NO ACTION: 자식에 해당 부모의 외래 키를 참조하는 행이 존재하면 작업 수행 X
INSERT 옵션
- AUTOMATIC: 부모 테이블의 PK가 자동 생성된 후 자식에 해당 기본 키를 참조하는 FK를 포함하여 데이터 삽입
- SET NULL: 부모에 PK가 없다면 자식의 FK를 널로 설정
- SET DEFAULT: 부모에 PK가 없다면 자식의 FK를 기본값으로 설정
- DEPENDENT: 부모의 PK가 존재할 때만 자식에 데이터 삽입 가능
- NO ACTION: 참조되는 FK 없다면 자식에 데이터 삽입 불가능
📌 DCL
GRANT
1
2
3
4
5
6
7
8
9
10
| GRANT 권한목록
ON 객체명
TO 사용자명;
/*
SELECT: 데이터를 조회할 수 있는 권한
INSERT: 데이터를 삽입할 수 있는 권한
UPDATE: 데이터를 수정할 수 있는 권한
DELETE: 데이터를 삭제할 수 있는 권한
ALL PRIVILEGES: 모든 권한을 부여
*/
|
1
2
3
4
| GRANT SELECT, INSERT
ON employees
TO user1;
-- 특정 권한 부여
|
1
2
3
4
| GRANT ALL PRIVILEGES
ON employees
TO user2;
-- 모든 권한 부여
|
1
2
3
4
| GRANT SELECT
ON DATABASE company_db
TO user3;
-- 특정 데이터베이스에 권한 부여
|
REVOKE
1
2
3
4
5
6
7
8
9
10
| REVOKE 권한목록
ON 객체명
FROM 사용자명;
/*
SELECT: 데이터를 조회할 수 있는 권한
INSERT: 데이터를 삽입할 수 있는 권한
UPDATE: 데이터를 수정할 수 있는 권한
DELETE: 데이터를 삭제할 수 있는 권한
ALL PRIVILEGES: 모든 권한을 부여
*/
|
1
2
3
| REVOKE SELECT, UPDATE
ON employees
FROM user2;
|
1
2
3
| REVOKE ALL PRIVILEGES
ON employees
FROM user3;
|
📌 연산자 우선순위
- 괄호 → NOT → 비교, SQL 연산자 → AND → OR