[Spark] Streaming
📌 Spark Streaming
Spark Streaming 은 실시간으로 들어오는 데이터 스트림을 처리하기 위한 Spark Core API의 확장 라이브러리이다. 이벤트 단위 스트림 처리가 아니라 마이크로 배치 처리 방식으로 동작한다.
이벤트 단위 스트림 처리는 데이터가 시스템에 도착하는 즉시 이벤트를 바로 처리하는 방법이다. 반면 마이크로 배치 처리는 데이터를 짧은 시간 간격 동안 수집하고, 해당 배치를 하나의 단위로 처리하는 방법이다.
Spark Streaming의 가장 핵심 개념은 Discretized Stream, DStream 이다. DStream은 실시간 데이터 스트림을 나타내는 고수준 추상화로, 내부적으로 연속적인 RDD의 시퀀스로 구성된다.
Spark Streaming은 데이터 스트림을 짧은 시간 간격으로 자르고, 각 시간 간격 동안 수집된 데이터는 하나의 RDD로 변환된다. 이러한 RDD들이 연속적으로 이어져 있는 것이 DStream이다. 이는 곧 DStream에 RDD 연산을 사용할 수 있다는 것을 의미한다.
동작 과정
- Kafka, HDFS, S3 등과 같은 데이터 소스로부터 데이터를 실시간으로 수신한다.
- 수신된 데이터를 일정한 시간 간격으로 묶에 RDD를 생성하고 RDD들의 연속인 DStream을 만든다.
- DStream의 각 RDD에 대해 transformation 연산을 병렬로 진행한다.
- 처리된 결과를 내보낸다.
📌 Structured Streaming
Structured Streaming 은 데이터 스트림을 ‘무한 테이블’로 간주한다. 새로운 데이터가 도착할 때마다 이 데이터는 마치 무한 테이블에 새로운 행으로 추가되는 것처럼 취급된다. 이 개념은 스트리밍 데이터에 DataFrame 및 SQL 연산을 그대로 적용할 수 있다는 의미이다.
동작 과정
- 정해진 트리거 간격마다 스파크는 데이터 소스에서 마지막으로 확인한 시점 이후 도착한 새로운 데이터가 있는지 확인한다.
- 새로운 데이터는 하나의 배치로 간주되며 사용자가 정의한 쿼리가 이 배치에 적용된다.
- 쿼리가 실행되면 중간 연산 결과가 담기게 되며, 결과 테이블이 업데이트된다.
- 결과 테이블에서 변경된 부분을 내보낸다.
Event Time 기반 처리
Structured Streaming은 데이터가 시스템에 도착한 시간이 아닌 이벤트가 실제로 발생한 시간을 기준으로 연산을 수행할 수도 있다.
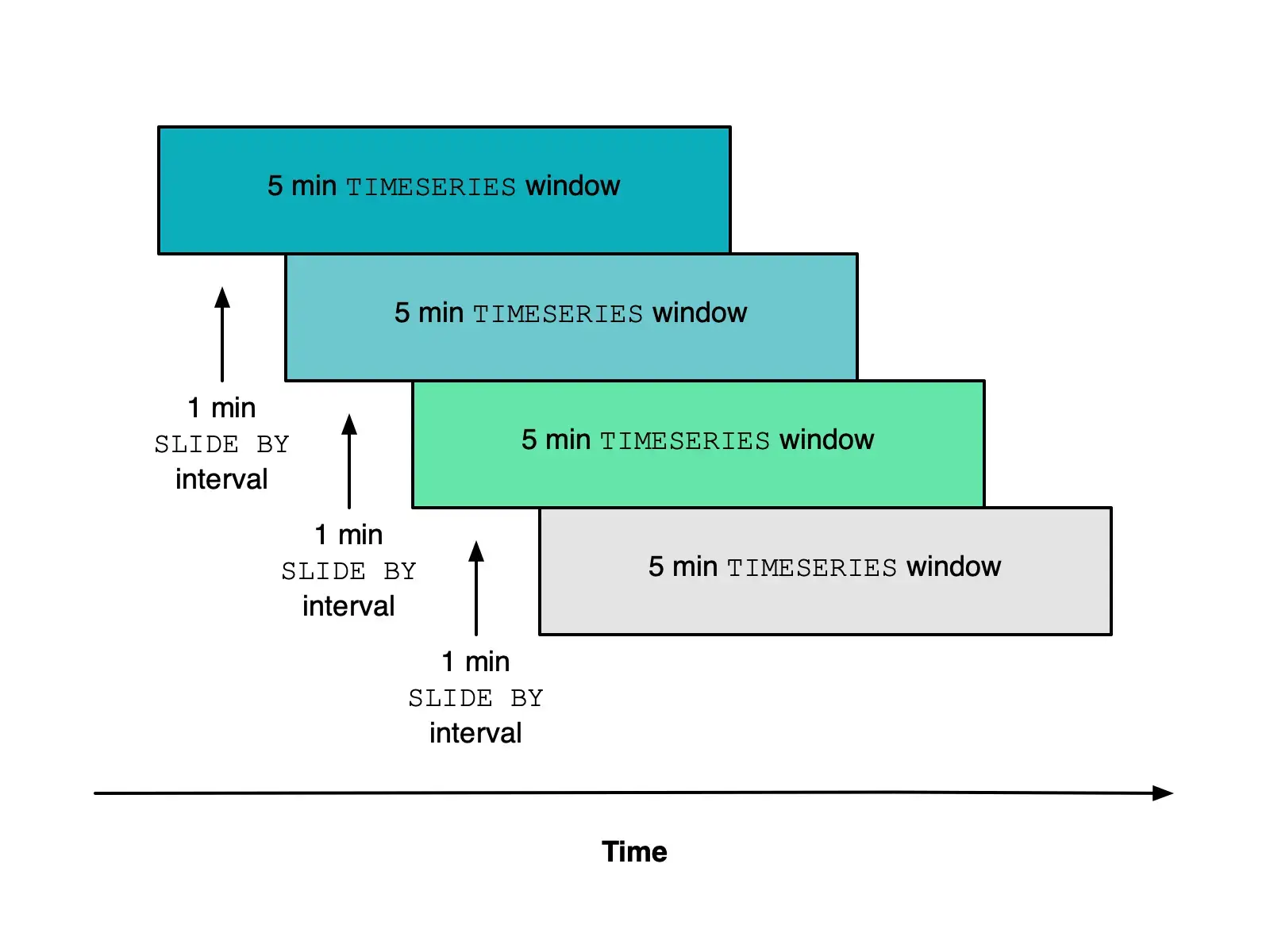
‘윈도우 연산’은 특정 시간 단위로 데이터를 그룹화하여 집계하는 기능으로, 주로 sliding window 기법을 사용한다. 시계열 데이터를 분석할 때 특히 유용하다.
예를 들어 5분 크기의 윈도우를 1분 간격으로 슬라이딩하는 상황은 위 그림과 같다.
네트워크 지연 등으로 데이터가 발생된 순서대로 도착하지 않을 수 있는데, Structured Streaming은 Watermarking 이라는 방식으로 이 문제를 해결한다. Watermark 는 윈도우 계산을 위해 데이터를 기다릴 최대 시간이다. 예를 들어 워터마크를 10분으로 설정하면, 해당 윈도우 계산에 10분까지 늦게 도착하는 데이터는 결과에 포함한다.
관련 메서드
1
2
sc = SparkContext("local[2]", "NetworkWordCount")
ssc = StreamingContext(sc, 10)
StreamingContext 는 스파크 스트리밍의 entrypoint를 생성한다.
두 번째 인자는 배치 간격을 의미하는데, 10으로 설정하면 ‘데이터 스트림을 10초 간격으로 자르겠다’는 의미이다.
1
lines = ssc.socketTextStream("127.0.0.1", 9999)
socketTextStream 은 지정된 TCP 소켓으로부터 텍스트 데이터를 실시간으로 수신하여 DStream을 생성하는 메서드이다.
첫 번째 인자는 데이터를 보낼 서버의 IP 주소, 두 번째 인자는 서버의 포트 번호이다.
socketTextStream 이 호출되고 스트리밍 컨텍스트가 시작(ssc.start())되면, 스파크는 클러스터의 executor 중 하나에 Receiver 라는 태스크를 실행시킨다. 이 리시버는 지정된 호스트와 TCP 연결을 맺고, 수신 대기한다. 데이터가 들어오면 리시버는 이를 수집하여 메모리에 Block 형태로 저장한다. 설정된 배치 간격마다 수집된 데이터 블록들은 하나의 RDD로 변환되고, RDD들의 연속적인 스트림이 DStream이 된다.
1
ssc.awaitTermination()
awaitTermination 은 스파크 스트리밍 애플리케이션의 드라이버가 바로 종료되는 것을 막고 스트리밍 작업이 계속 진행되도록 대기시키는 역할을 하는 메서드이다. 스트리밍은 명시적으로 중단되기 전까지는 지속적으로 실행되어야 하는데, 일반적인 프로그램은 마지막 코드를 실행하면 자동으로 종료된다. 이러한 문제를 방지하기 위해 awaitTermination 은 현재 쓰레드를 차단하여 사용자가 직접 중단하거나, 예외가 발생하지 않는 이상 계속 대기한다.
timeout 파라미터를 설정하여 대기할 최대 시간을 명시할 수 없다. 만약 없다면 무한정 대기한다.
1
2
3
4
5
6
7
8
9
10
11
spark = SparkSession \
.builder \
.appName("StructuredNetworkWordCount") \
.getOrCreate()
lines = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.load()
readStream 은 스트리밍 데이터를 읽기 위한 인터페이스를 리턴한다.
format 은 데이터 소스의 형식을 지정한다. socket 은 지정된 TCP 소켓을 통해 들어오는 데이터를 읽으며, rate 는 실제 외부 데이터 소스 없이 클러스트의 스트리밍 성능을 벤치마킹할 때 설정한다. file 은 파일 단위로 데이터가 주기적으로 생성될 때 사용한다. kafka 는 이름 그대로 카프카로부터 실시간 데이터를 수신할 때 사용한다.
이후 option 을 통해 데이터 소스 서버의 IP 주소와 호트 번호를 명시할 수 있으며, load 를 통해 정의된 설정을 바탕으로 스트리밍 데이터프레임을 생성한다.
1
2
3
4
5
6
7
query = wordCounts \
.writeStream \
.outputMode("complete") \
.format("console") \
.start()
query.awaitTermination()
writeStream 은 스트리밍 데이터를 쓰기 위한 인터페이스를 리턴한다.
outputMode 는 결과 테이블이 업데이트될 때마다 어떤 데이터를 외부로 내보낼지를 결정한다. complete 로 설정되면 매 트리거마다 전체 결과 테이블의 모든 내용을 내보내며, append 로 설정되면 새롭게 추가된 행만, update 로 설정되면 내용이 변경된 행만 내보낸다.
start 는 정의된 모든 설정을 바탕으로 실제 쿼리 실행을 시작하는 action 연산이다.
Processing Model
Structured Streaming의 전체적인 동작 과정에 대해 알아보자.
- 데이터프레임 또는 SQL API를 통해 스트리밍 쿼리를 작성한다.
- 작성된 쿼리는 catalyst optimizer를 포함하고 있는 스파크 SQL 엔진으로 전달된다.
- 스파크 SQL 엔진은 이를 컴파일하고 논리적 및 물리적 계획을 수립한다.
start메서드를 호출하면 실제로 스트리밍 처리가 이루어진다. 드라이버 프로세스 내 별도의 쓰레드가 생성된다.- 생성된 별도의 쓰레드는 정해진 트리거에 따라 반복적으로 작업을 수행한다. 이 과정은 이전 Streaming의 동작 과정과 동일하다(데이터를 읽고, 새로운 데이터가 있는지 확인하는 동작 등).
트리거 설정
Trigger 는 언제, 얼마나 자주 스트리밍 소스의 새로운 데이터를 처리하여 마이크로 배치를 실행할지 결정하는 설정이다. 트리거 설정 종류는 다음과 같다.
Unspecified: 하나의 마이크로 배치가 완료되면 즉시 다음 마이크로 배치를 시작한다. 지연 시간을 가능한 낮게 유지하면서 클러스터의 모든 가용 리소스를 활용하여 최대 처리량을 내고 싶을 때 사용한다.Fixed Interval: 고정된 시간 간격마다 새로운 마이크로 배치를 실행하도록 설정한다. 이전 배치의 처리 시간이 설정된 간격보다 짧으면 다음 간격이 될 때까지 대기하며, 이전 배치의 처리 시간이 간격보다 길어지면 즉시 다음 배치를 시작한다.One-Time: 쿼리가 시작될 때 그 시점에 사용 가능한 모든 데이터를 단 하나의 마이크로 배치로 처리한 후 쿼리를 자동으로 중단한다. 데이터가 너무 많으면 메모리 관련 문제가 발생할 수 있다.Available Now:One-Time과 전체적으로 유사하나, 데이터를 여러 개의 마이크로 배치로 나누어 처리할 수 있다.Continuous Processing: 마이크로 배치 개념을 사용하는 것이 아닌 이벤트 단위 스트림 처리와 유사하게 데이터가 도착하는 즉시 처리하는 방법이다. 지연 시간을 극한까지 낮출 수 있다. 최소 한 번의 처리 보장을 지원한다.
1
2
3
4
5
6
7
spark = SparkSession \
.builder \
.appName("StructuredStreamingSum") \
.config("spark.streaming.stopGracefullyOnShutdown", "true") \
.config("spark.sql.streaming.schemaInference", "true") \
.config("maxFilesPerTrigger", 1) \
.getOrCreate()
spark.streaming.stopGracefullyOnShutdown 을 true 로 설정하면 스파크 스트리밍 애플리케이션이 종료될 때 모든 실행 중인 배치 연산이 끝난 뒤 gracefully하게 종료되도록 한다.
spark.sql.streaming.schemaInference 를 true 로 설정하면 스트리밍 소스를 읽을 때 자동으로 스키마를 추론한다.
maxFilesPerTrigger 에 하나의 트리거에 처리할 최대 파일 개수를 지정한다.
1
2
3
4
5
6
7
8
9
10
query = shorten_df \
.writeStream \
.format("json") \
.option("path", "streaming_output") \
.option("checkpointLocation", "checkpoint") \
.outputMode("append") \
.trigger(processingTime='5 seconds') \
.start()
query.awaitTermination()
checkpointLocation 은 체크포인트를 활성화하고 관련 메타데이터를 저장할 디렉터리를 지정하는 옵션이다. 어디까지 데이터를 읽었는지에 대한 정보인 오프셋, 어떤 배치가 성공적으로 처리되었는지에 대한 정보인 커밋, 중간 집계 값이나 상태 정보를 저장한다.
체크포인트란 Structured Streaming이 쿼리의 진행 상황과 상태를 저장소에 지속적으로 저장하는 메커니즘이다.
trigger 는 새로운 마이크로 배치를 언제, 얼마나 자주 실행할지 결정하는 메서드이다. processingTime 옵션에 interval을 설정한다.
Fault Tolerance
Structured Streaming의 궁극적인 목표는 다음과 같다.
- 모든 입력 데이터는 최소 한 번 이상 처리된다.
- 출력 시스템에는 동일한 결과가 두 번 이상 기록되지 않는다.
이를 만족하기 위해 데이터 소스는 특정 오프셋으로부터 데이터를 다시 읽어올 수 있어야 하며, 스파크는 checkpoint 와 Write-Ahead Logs, WAL 를 통해 각 마이크로 배치의 오프셋을 저장소에 저장한다.
스파크가 특정 배치를 시작할 때 처리할 데이터의 범위를 WAL에 기록한 후, 성공적으로 완료되면 해당 오프셋 범위를 체크포인트에 커밋한다.
만약 처리 도중 애플리케이션이 실패하면 재시작된 애플리케이션은 체크포인트를 확인하고, 성공적으로 완료된 배치의 오프셋을 확인하고, 해당 오프셋 다음부터 데이터를 다시 요청한다.
동일한 입력에 대해 재처리가 발생했을 때, 이전과 동일한 결과가 나와야 하며 동일한 연산을 여러 번 수행하더라도 그 결과가 단 한 번 수행했을 때와 동일하게 유지되어야 한다.
📌 참고
https://docs.newrelic.com/kr/docs/nrql/using-nrql/create-smoother-charts-sliding-windows/