[Spark] Apache Spark란?
📌 Apache Spark란?
Apache Spark 는 빅데이터를 효과적으로 처리하기 위한 분석 엔진이다. Hadoop 의 MapReduce 가 디스크 기반으로 처리하는 반면, Spark는 인메모리 기반 병렬 연산을 진행한다.
일반적으로 Spark가 Hadoop MapReduce보다 100배 정도 빠르다.
📌 특징
- 배치 프로세싱을 통해 일정 시간 간격으로 데이터를 처리할 수 있다.
- 스트리밍 프로세싱을 통해 실시간 데이터를 처리할 수 있다. Spark의
Structured Streaming라이브러리는 데이터 스트림을 계속해서 행이 추가되는 무한한 테이블로 간주하기 때문에, 실시간으로 들어오는 데이터를 작은 단위로 나누어 즉각적으로 데이터를 처리할 수 있다. - 분산 클러스터 컴퓨팅을 통해 서로 데이터를 교환할 수 있다. Spark는 높지 않은 스펙의 노드들을 네트워크로 연결하여 하나의 거대한 노드처럼 사용한다. 이를
scale-out이라고 한다. HDFS,S3등과 같은 데이터 저장소와 통합될 수 있다. Spark 자체는 계산만 담당하며, 특정 저장소에 종속되지 않는다. 즉, Spark는 계산 엔진과 저장소가 분리되어 있다.- 파이썬, 스칼라, R, SQL 등과 같은 프로그래밍 언어를 지원한다.
- 배치 프로세싱과 스트리밍 프로세싱을
wrapper만 수정하여 사용할 수 있다. 배치 데이터 로직과 스트리밍 데이터 처리 로직이 거의 동일하기 때문이다.
📌 구조

하나의 클러스터는 하나의 master node 와 여러 개의 worker node 로 구성된다.
위 그림에서 왼쪽 노드가 master node이다.
cluster manager는 전체 클러스터를 모니터링하고 리소스를 적절히 분배한다.
master node는 driver 프로세스를 수행한다. 작성한 코드를 분석하여 plan을 수립하며, worker node의 상태를 모니터링한다.
반면 worker node는 executor 프로세스를 수행한다. master node로부터 할당받은 작업을 수행하고 데이터를 메모리에 저장하며, 다른 worker node와 데이터를 교환할 수 있다.
애플리케이션 실행 프로세스
- 사용자가 Spark 애플리케이션을 실행하면 먼저 driver 프로세스가 시작된다. 드라이버 내부에
SparkContext객체가 생성된다.SparkContext객체는 Spark 모든 기능에 대한 entrypoint이다. SparkContext가YARN,k8s와 같은 클러스터 매니저와 통신하여 필요한 자원을 요청한다. 클러스터 매니저는 요청을 받고 여러 worker node에 자원을 할당하고 worker node 위에서 executor 프로세스를 실행시킨다.- executor가 실행되면 driver에게 자신의 위치를 등록한다. 즉, 드라이버는 이 시점에 어떤 executor가 어디서 동작하는지 알게 된다. 사용자의
action이 호출되면 드라이버는 이를job으로 변환하고 여러 개의stage로 나눈다. 각stage는 여러 개의task로 쪼개진다. 드라이버는 이task를 executor에 직접 전달하여 실행을 지시한다. - 각각의 executor는 할당받은 태스크를 병렬로 실행하고, 그 결과를 드라이버에 보고한다.
각각의 executor는 자신이 계산한 파티션을 자신의 메모리나 디스크에 캐싱하는데, 이를 통해 동일한 데이터를 반복적으로 사용하는 경우 성능이 향상된다.
groupby, join 과 같이 데이터의 재분배가 필요한 연산을 수행할 때 각 executor는 다른 executor와 네트워크를 통해 데이터를 주고받는데, 이 과정을 shuffling 이라고 한다. 다만 shuffling 은 디스크 I/O와 네트워크 통신 모두 사용하기 때문에 비용이 큰 연산이며, 이를 최소화하는 것이 Spark 성능 튜닝의 핵심이다.
groupby나join은 관련 있는 데이터끼리 한 곳에 모아야 하는 연산이기 때문에 데이터 재분배가 필요한 것이다.
클러스터의 종류
- 온프레미스 클러스터는 자체적인 데이터 센터의 물리적 서버를 통해 직접 구축하는 클러스터이다. 초기 비용은 높으나 이후 추가적인 인프라 비용은 거의 없으나, 직접 유지보수해야 한다는 단점이 있다.
- 클라우드 기반 클러스터는 AWS EMR, Google Dataproc, Azure HDInsight와 같이 클라우드 벤더에서 제공하는 서비스를 통해 사용하는 클러스터이다. 확장성이 좋고 관리 측면에서 편리하나, 지속적인 운영 비용이 발생한다.
- 하이브리드 클러스터는 온프레미스와 클라우드 기반 클러스터를 혼용하여 사용하는 방법이다. 평소에는 온프레미스 클러스터를 사용하다, 트래픽 피크가 발생하면 클라우드로부터 추가 노드를 임시로 대여하여 확장성을 챙긴다.
클러스터의 장점
- 병럴 처리 방식을 통해 작업 수행 시간을 단축시킬 수 있다.
- scale-out 모델을 채택하므로 상대적으로 비용이 저렴하며, 수평적으로 노드를 추가할 수 있어 유연하게 관리할 수 있다.
- 특정 노드에 문제가 발생했을 때 자동으로 다른 노드가 그 작업을 대신 수행하여 안정성을 유지한다. 이를
Fault Tolerance라고 한다.
YARN 아키텍처
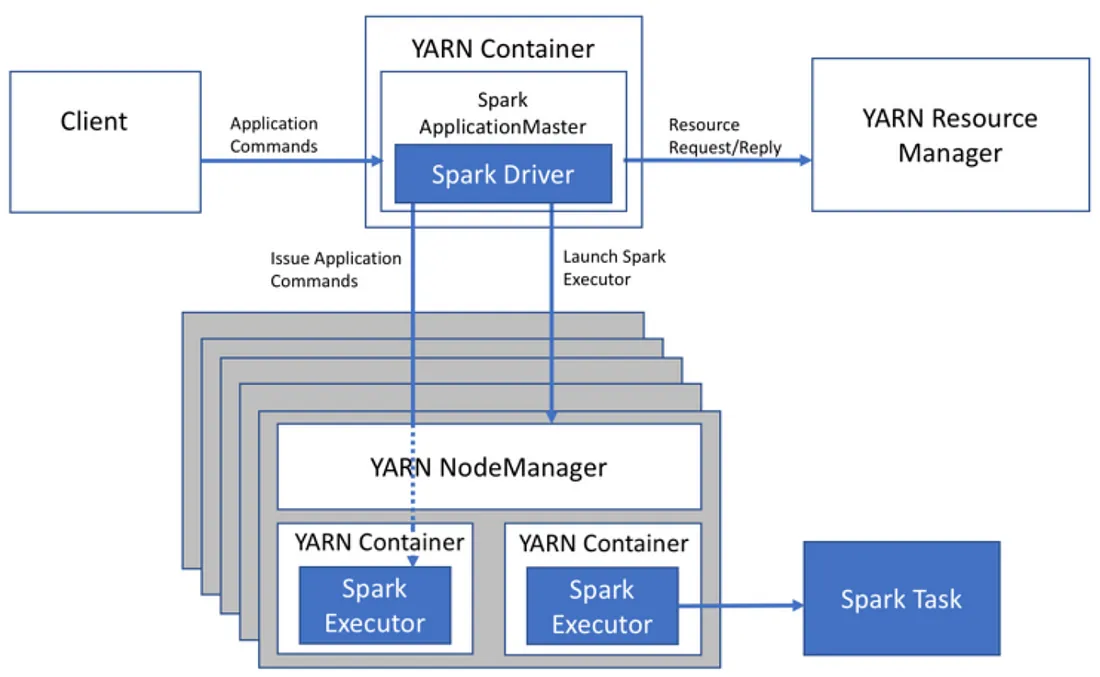
ResourceManager는 master node에서 실행된다. 클러스터의 모든 자원을 관리하며 어떤 애플리케이션에 자원을 할당할지 결정한다.NodeManager는 slave node에서 실행되며, 자신이 속한 노드의 자원 상태를 지속적으로 ResourceManager에게 보고하고, ResourceManager의 명령을 받아Container를 실행하고 관리한다.ApplicationMaster는 애플리케이션 당 하나 존재하는 컨테이너로, 생명주기를 관리한다. ResourceManager를 통해 필요한 컨테이너를 할당받고, 해당 컨테이너에 task가 실행되도록 NodeManager에 요청한다.Container는 NodeManager가 관리하는 자원 할당 단위로, 실제 task가 컨테이너 안에서 실행된다.
구체적인 실행 프로세스는 다음과 같다.
- Spark 또는 MapReduce job을 클러스터에 제출한다. 클라이언트는 ResourceManager에게 애플리케이션 실행을 요청한다.
- 요청을 받은 ResourceManager는 ApplicationMaster 프로세스를 컨테이너 안에서 시작시킨다.
- ApplicationMaster는 관리할 애플리케이션의 요구사항을 파악한 후 ResourceManager에게 필요한 자원을 직접 요청한다.
- ResourceManager는 요청받은 컨테이너를 여러 NodeManger에게 할당한다. ApplicationMaster에게 요청한 컨테이너를 어느 노드에서 사용할 수 있는지에 대한 정보를 전달한다.
- 컨테이너 위치 정보를 받은 ApplicationMaster는 NodeManager와 직접 통신하여 컨테이너에 실제 task를 실행하도록 지시한다.
- 모든 task가 완료되면 ResourceManager에게 등록을 해제하고, 자원을 클러스터에 반납한다.
PySpark 아키텍처
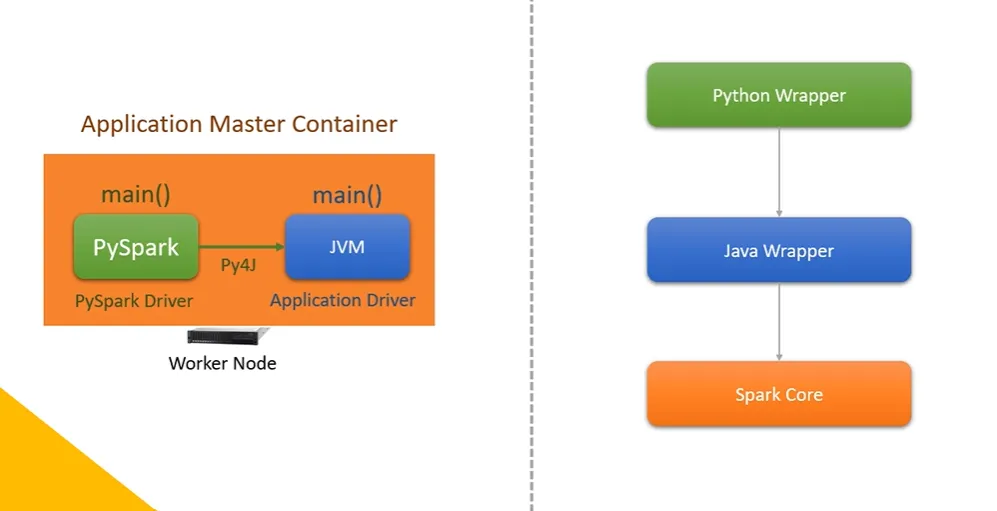
PySpark 애플리케이션은 파이썬과 자바가 유기적으로 결합하여 동작하는 하이브리드 구조이다. 작업 지시는 파이썬, 실행은 JVM에서 이루어진다. 이들을 직접 소통할 수 없는데, Py4J 라이브러리가 둘 사이 다리 역할을 한다.
구체적인 실행 프로세스는 다음과 같다.
- PySpark 애플리케이션을 실행하면 파이썬 인터프리터 프로세스가 시작되고,
SparkSession객체를 생성한다. - 이후 파이썬 드라이버는 내부적으로 JVM을 실행하고 Py4J 라이브러리를 통해 JVM과 소켓 통신으로 연결된다.
- 이후 작업은 이전과 같다.
생성된 태스크를 executor에 전달하여 실행을 지시할 때, 연산의 종류에 따라 실행 방식이 달라진다.
select, filter, groupBy 와 같이 데이터프레임에 최적화된 내장 함수들은 전부 executor JVM에서 스칼라 코드로 실행된다. 따라서 파이썬과 JVM 간 데이터 이동이 없어 빠르고 효율적이다.
사용자 정의 함수(UDF)나 RDD의 map 연산처럼 파이썬 워커가 필요한 경우 JVM은 별도의 파이썬 워커 프로세스를 실행한다. executor JVM은 처리할 데이터 파티션을 직렬화한 후 소켓을 통해 파이썬 워커로 전송하여 연산을 처리한 후, 다시 직렬화하여 JVM으로 돌려보낸다.
📌 구성 요소
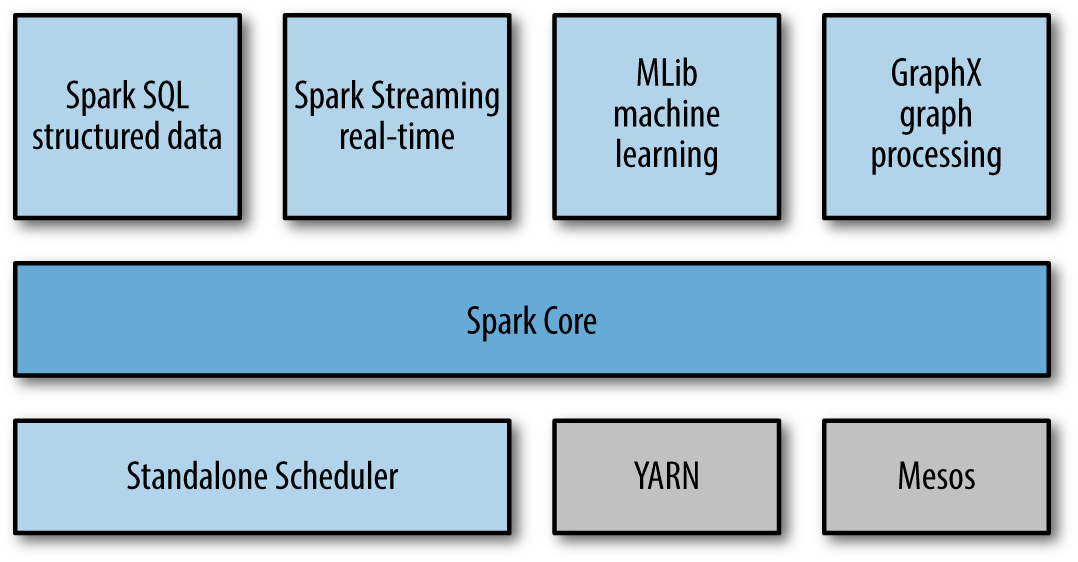
Spark는 여러 컴포넌트들이 층을 이루고 있는 통합 분석 엔진이다. 모든 컴포넌트들은 Spark Core 라는 핵심 엔진 위에서 동작한다. Spark Core 는 기본적인 입출력, 메모리 관리 장애 복구와 같이 대규모 데이터 처리에 필요한 저수준 기능을 담당하며, Spark의 기본 데이터 모델인 RDD(Resilient Distributed Dataset) API를 제공한다.
Spark Core 위에서 동작하는 네 가지 고수준 라이브러리를 알아보자.
Spark SQL은 (반)정형 데이터를 다루기 위한 컴포넌트이며, SQL 쿼리 또는DataFrame을 통해 쉽게 데이터를 다룰 수 있도록 한다. 작성된 SQL 쿼리 또는 DataFrame을Catalyst Optimizer라는 쿼리 최적화 엔진을 통해 효율적인 RDD 연산 plan으로 변환한 후 처리한다.
Spark의 DataFrame은 RDD에 스키마를 부여한 것이다.
Spark Streaming은Kafka등으로부터 실시간으로 들어오는 데이터를 처리하기 위한 컴포넌트이다. 내부적으로 데이터 스트림을 짧은 시간 단위의 마이크로 배치로 나눈 후 처리한다.MLlib은 빅데이터를 위한 머신러닝 라이브러리로, 모든 알고리즘에 병렬로 실행되도록 설계되었다.GraphX는 그래프 형태의 데이터를 분석하기 위한 컴포넌트로PageRank,Connected Components와 같은 그래프 알고리즘을 실행할 수 있는 API를 제공한다.
📌 RDD와 특징
RDD(Resilient Distributed Dataset) 은 여러 서버에 분산되어 병렬로 처리될 수 있는 불변 데이터 요소의 컬렉션이다. 불변성이 RDD의 가장 중요한 특징 중 하나인데, 기존 RDD를 통해 새로운 RDD를 생성하기 위해 map 이나 filter 와 같은 연산을 사용해야 한다.
RDD는 하나의 거대 데이터 덩어리가 아니라 여러 개의 작은 파티션으로 나뉘어 클러스터의 여러 워커 노드에 분산 저장된다. Spark는 각각의 파티션을 하나의 논리적인 데이터셋으로 다룬다.
Spark는 RDD가 어떤 과정을 통해 생성되었는지에 대한 정보(lineage)를 기억한다. 특정 워커 노드가 다운되어 일부 파티션이 유실된다면, 기억한 정보를 통해 사라진 파티션을 계산하여 복구한다.
Spark는 transformation, action 두 가지 연산을 가지고 있는데, 변환 연산은 호출되는 즉시 실행되는 것이 아니라, 액션 연산이 호출되면 정의된 모든 변환 연산이 실제로 수행된다. 이를 lazy evaluation 이라고 한다.
📌 pyspark의 기본적인 메서드
1
sc = pyspark.SparkContext('local[*]')
SparkContext 메서드의 master 파라미터는 Spark 작업을 어디서 실행할지 지정하는 클러스터 URL이다. local[*] 로 설정하면, 클러스터가 아닌 로컬 머신에서 Spark를 실행하겠다는 의미이다. 대괄호 안에는 사용할 코어의 수를 입력하며, asterisk를 입력하면 사용 가능한 모든 CPU 코어를 최대한 활용한다.
SparkContext 는 싱글턴 패턴으로 설계되었기 때문에 하나의 Spark 애플리케이션 내에는 오직 하나의 SparkContext 만 존재할 수 있다. 따라서 생성돤 sc 를 계속해서 재활용할 수 있다.
이미 SparkContext 가 실행 중인 상태에서 SparkContext 메서드를 호출하면 오류가 발생하는데, 이미 생성된 context를 안전하게 가져오기 위해 getOrCreate 메서드를 자주 사용한다.
1
2
rdd = sc.parallelize(range(1000))
rdd.takeSample(False, 5)
parallelize 메서드는 리스트나 튜플같은 파이썬 컬렉션을 RDD로 변환한다. parallelize(range(1000)) 는 0부터 999까지의 숫자가 있는 RDD를 생성하고 이들을 여러 파티션에 나눈다. 두 번째 인자로 파티션의 개수인 numSlices 를 받을 수 있다.
takeSample 메서드는 RDD에서 무작위로 일부 데이터를 추출하여 가져오는 action 연산이다. 첫 번째 인자인 withReplacement 는 복원 추출 여부이며, 두 번째 인지안 num 은 추출할 데이터의 개수를 지정한다.
1
2
3
4
from operator import add
rdd = sc.parallelize([("a", 2), ("b", 3), ("a", 3)])
sorted(rdd.reduceByKey(add).collect())
reduceByKey(add) 는 RDD의 각 키에 대해 값을 더하는 작업을 수행한다. 셔플링 전 각 워커 노드는 자신의 파티션에서 먼저 집계 연산을 수행한다. 이렇게 부분적으로 집계된 결과들을 동일한 키를 기준으로 셔플링한다. 이를 통해 네트워크 부하를 최소화할 수 있다.
collect 는 분산된 RDD의 모든 요소를 수집하여 메모리로 가져오는 action 연산이다.
📌 참고
https://wjrmffldrhrl.github.io/spark-1/